
简介
在我们了解了bug的工作原理后,并将这些细节发送给Chrome以帮助他们开始修复之后,我们回到了其他项目。这个bug仍然是一个讨论的话题,我们没有理由不为它编写exploit。
这样做的一个主要原因是了解Chrome网络栈中的漏洞有多容易被利用,因为进程架构的变化相对较晚。团队中没有人认真考虑过利用Chrome网络堆栈中的问题,因此相对于代码库中更广为人知的区域(例如renderer错误或更典型的浏览器进程沙盒逃逸漏洞),它可能会提供一些更值得关注的见解。
我们的许多失败并不是由于任何特殊的困难,而是由于粗心大意,在处理不可靠的原语时,这种粗心大意似乎更成问题;很容易花一整天调试失败的堆,而没有注意到Web服务器在错误的端口上运行…
Chapter 4:Exploit
上篇文章,我们使用了一个非常强大的原语;该漏洞让我们在堆分配结束后写入指定大小的可控数据。只有一个主要的缺点需要克服——由于bug的工作方式,我们覆盖的分配总是大小为0。
与大多数其他分配器一样,tcmalloc 以最小的类大小存储它,在本例中最大为16个字节。size类有两个问题。首先,“useful”对象(即那些包含我们可能要覆盖的指针对象)通常大于这个值。其次,size类相当阻塞,因为几乎每个IPC对网络进程的调用都会触发其中的分配和释放。因此,我们不能使用“heavy” 获取API来进行堆喷射/清理。不幸的是,在网络进程中很少有对象类型可以容纳16个字节,并且创建这些对象类型不会触发大量其他的分配。
也有一些好消息。如果网络进程崩溃,它将以默认方式重新启动,因此,如果我们正在努力提高可靠性,我们能够将此作为一个支撑 — 我们的exploit在成功之前可以尝试几次。
NetToMojoPendingBuffer
通过枚举与网络进程相关的类,我们能够相对快速地找到适合于构造“write-what-where”(任意写)原语的对象。在每个URLLoader::ReadMore调用上都会创建一个新的NetToMojoPendingBuffer对象,因此攻击者可以通过延迟在Web服务器分配响应块来控制这些分配。
class COMPONENT_EXPORT(NETWORK_CPP) NetToMojoPendingBuffer
: public base::RefCountedThreadSafe<NetToMojoPendingBuffer> {
mojo::ScopedDataPipeProducerHandle handle_;
void* buffer_;
};
我们不需要担心覆盖handle_因为当Chrome遇到一个无效的handle,它只是提前返回而不会崩溃。将要写入缓冲区备份存储的数据正是下一个HTTP响应块,因此也受到了完全控制。
不过,有一个问题 — 如果没有单独的信息泄漏,单靠原语是不够的。使功能更强大的一个明显方法是对buffer_ 进行部分覆盖,然后破坏其他size类中的对象(希望更方便)。但是,指针永远不会被分配到常规堆地址。相反,NetToMojoPendingBuffer对象的备份存储是在一个共享内存区域中分配的,这个区域只用于IPC,不包含对象,所以不会破坏任何东西。
除了NetToMojoPendingBuffer,我们在16字节大小的类中找不到任何立即有用的东西。
寻找STL容器
幸运的是,我们并不局限于c++类和结构。相反,我们可以针对任意大小的缓冲区,比如容器备份存储。当一个元素被插入到一个空的std::vector中时,我们为一个单独的元素分配一个存储空间。在随后的插入中,如果没有剩余的空间,它就会加倍。其他一些容器类似的方式操作。因此,如果我们精确地控制对指针向量的插入,我们可以对其中一个指针执行部分覆盖,从而将bug转变为某种类型的混淆。
WatcherDispatcher
在我们尝试使用 NetToMojoPendingBuffer 时,出现了与 WatcherDispatcher 相关的崩溃。WatcherDispatcher类不是特定于网络进程的。它是基础的Mojo结构之一,用于IPC消息发送和接收。类结构如下:
class WatcherDispatcher : public Dispatcher {
using WatchSet = std::set<const Watch*>;
base::Lock lock_;
bool armed_ = false;
bool closed_ = false;
base::flat_map<uintptr_t, scoped_refptr<Watch>> watches_;
base::flat_map<Dispatcher*, scoped_refptr<Watch>> watched_handles_;
WatchSet ready_watches_;
const Watch* last_watch_to_block_arming_ = nullptr;
};
class Watch : public base::RefCountedThreadSafe<Watch> {
const scoped_refptr<WatcherDispatcher> watcher_;
const scoped_refptr<Dispatcher> dispatcher_;
const uintptr_t context_;
const MojoHandleSignals signals_;
const MojoTriggerCondition condition_;
MojoResult last_known_result_ = MOJO_RESULT_UNKNOWN;
MojoHandleSignalsState last_known_signals_state_ = {0, 0};
base::Lock notification_lock_;
bool is_cancelled_ = false;
};
MojoResult WatcherDispatcher::Close() {
// We swap out all the watched handle information onto the stack so we can
// call into their dispatchers without our own lock held.
base::flat_map<uintptr_t, scoped_refptr<Watch>> watches;
{
base::AutoLock lock(lock_);
if (closed_)
return MOJO_RESULT_INVALID_ARGUMENT;
closed_ = true;
std::swap(watches, watches_);
watched_handles_.clear();
}
// Remove all refs from our watched dispatchers and fire cancellations.
for (auto& entry : watches) {
entry.second->dispatcher()->RemoveWatcherRef(this, entry.first);
entry.second->Cancel();
}
return MOJO_RESULT_OK;
}
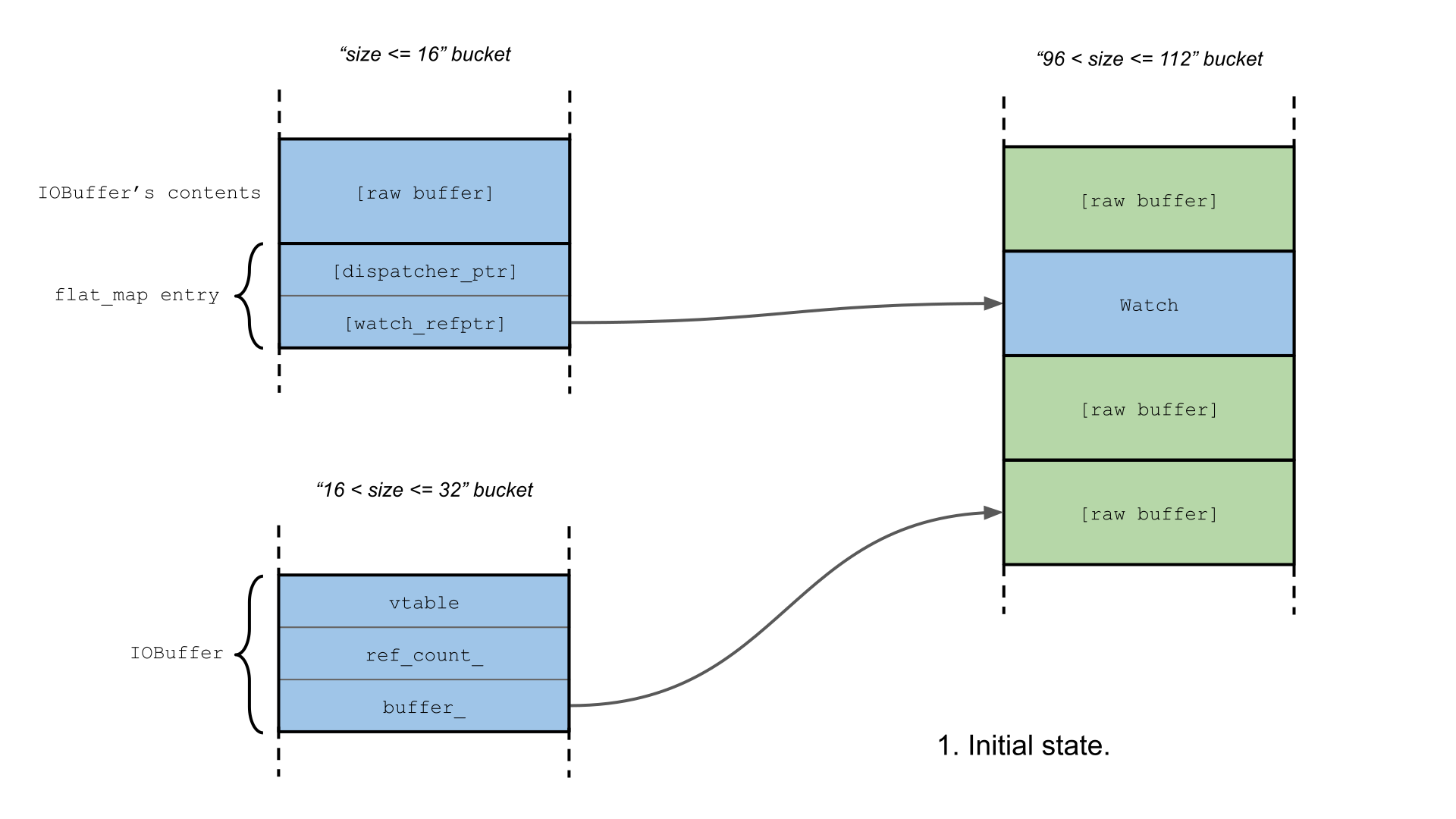
std::flat_map实际上是由std::vector支持的,并且watched_handles_只包含一个元素,它只需要16个字节。这意味着我们可以覆盖一个Watch指针!
Watch类的大小相对较大,为104字节,由于tcmalloc,我们只能针对大小相似的对象进行部分覆盖。标对象应该包含在某些偏移上的有效指针,以便在调用Watch方法后仍然有效。不幸的是,网络进程似乎不包含满足上述简单类型混淆要求的类。
我们可以利用Watch是一个引用计数类,我们的想法是喷射大量Watch-sized缓冲区,
tcmalloc将这些缓冲区放置在实际Watch对象的旁边,并希望scoped_refptr与覆盖的最少有效字节将指向我们的一个缓冲区。缓冲区应将第一个64位word(即fake引用计数)设置为1,其余的设置为0。在这种情况下,调用WatcherDispatcher::Close,释放scoped_refptr,将触发 fake Watch 的删除,析构函数将优雅地完成,缓冲区将被释放。
如果我们的缓冲区被计划任务发送到攻击者的服务器或返回到renderer进程,这将泄漏tcmalloc的屏蔽freelist指针,或者,更好的是一些有用的指针,如果我们设法在此期间分配其他东西。因此,我们现在需要的是能够在网络进程中创建这样的缓冲区,并延迟发送它们,直到发生破坏。
原来Chrome中的网络进程也负责处理WebSocket连接。重要的是WebSocket是一个低开销的协议,它允许传输二进制数据。如果我们让连接的接收端足够慢,并且发送足够的数据来填充操作系统套接字的发送缓冲区,直到TCPClientSocket::Write 变为“异步”操作,则后续对WebSocket::send的调用将导致原始帧数据被存储为IOBuffer 对象,每个调用只有两个额外的32字节分配。此外,我们可以通过修改接收端的延迟来控制缓冲区的存活时间。
看起来我们找到了一个近乎完美的堆喷射原语!不过它有一个缺点——不能释放独立的缓冲区。当大量发送或断开连接时,与连接相关的所有帧都会立即释放。显然,我们不能为每个spray对象建立WebSocket连接,并且上面的每个操作都会在堆中产生许多不希望的“noise”。不过,让我们暂时把它放在一边。
方法概述如下:
不幸的是,watched_handles_ 很快被证明是一个欠佳的目标。它的一些缺点是:
- 实际上有两个flatmap成员,但是我们只能使用其中的一个,因为破坏 watched_handles 将在RemoveWatcherRef虚函数调用期间立即触发崩溃。
- 每个
WatcherDispatcher分配在我们关注的size类中触发许多“noise”。 - 在Watch size类中,指针的LSB有16个(= 256 / GCD(112, 256))可能的值,其中大多数值甚至不会指向对象的头部。
尽管我们可以使用这种方法泄漏一些数据,但其成功率很低。该方法似乎是合理的,但是我们必须找到一个更“方便”的容器来覆盖。
WebSocketFrame
现在是时候仔细看看如何实现发送WebSocket frame了。
class NET_EXPORT WebSocketChannel {
[...]
std::unique_ptr<SendBuffer> data_being_sent_;
// Data that is queued up to write after the current write completes.
// Only non-NULL when such data actually exists.
std::unique_ptr<SendBuffer> data_to_send_next_;
[...]
};
class WebSocketChannel::SendBuffer {
std::vector<std::unique_ptr<WebSocketFrame>> frames_;
uint64_t total_bytes_;
};
struct NET_EXPORT WebSocketFrameHeader {
typedef int OpCode;
bool final;
bool reserved1;
bool reserved2;
bool reserved3;
OpCode opcode;
bool masked;
uint64_t payload_length;
};
struct NET_EXPORT_PRIVATE WebSocketFrame {
WebSocketFrameHeader header;
scoped_refptr<IOBuffer> data;
};
ChannelState WebSocketChannel::SendFrameInternal(
bool fin,
WebSocketFrameHeader::OpCode op_code,
scoped_refptr<IOBuffer> buffer,
uint64_t size) {
[...]
if (data_being_sent_) {
// Either the link to the WebSocket server is saturated, or several
// messages are being sent in a batch.
if (!data_to_send_next_)
data_to_send_next_ = std::make_unique<SendBuffer>();
data_to_send_next_->AddFrame(std::move(frame));
return CHANNEL_ALIVE;
}
data_being_sent_ = std::make_unique<SendBuffer>();
data_being_sent_->AddFrame(std::move(frame));
return WriteFrames();
}
WebSocketChannel使用两个独立的SendBuffer对象来存储传出帧。当连接饱和时,新的帧进入data_to_send_next_。而且,由于缓冲区是std::vector<std::unique_ptr<…>>,也可以成为覆盖的目标!但是,我们需要精确地计算在连接饱之前要发送的数据量,否则data_to_send_next_的缓冲区将很快变得太大,无法容纳16字节的插槽(Slot)。该值与exploit中的FRAMES_ENOUGH_TO_FILL_BUFFER常量绑定,取决于网络和系统配置。从理论上讲,该exploit可以自动计算值;我们只是在“本地主机”和“同一局域网”的情况下手动操作。另外,为了使饱和过程更加可靠,必须将WebSocket服务器套接字的SO_RCVBUF选项更改为一个相对较小的值,并且必须禁用数据压缩。
如上所述,我们的堆喷射技术为每个“desired”额外分配了两个32字节。不幸的是,WebSocketFrame,一个我们计划覆盖的指针,大小正好是32字节。这意味着,除非我们使用一些额外的堆操作技巧,否则在堆喷射期间生成的所有对象中只有1/3是正确的类型。另一方面,与Watch类相比,这个size类中LSB的值可能只有Watch类的一半,指向正确分配起始的几率更大。更重要的是,与WatcherDispatcher不同,WebSocket::Send不会触发16字节范围内的任何分配,除了调整我们所针对std::vector的大小之外,所以size类中的堆喷射应该是干净的。总的来说,这使得data_to_send_next_成为更好的目标。
分配方式
由于缺乏更好的替代方法,我们必须使用WebSocket::Send作为默认的堆操作工具。它至少负责:
- 使用32字节缓冲区进行喷射,我们希望覆盖其中一个WebSocketFrame指针。
- 插入目标向量条目并创建绑定的WebSocketFrame 。
- 分配IOBuffer 对象代替释放的缓冲区。
![]()
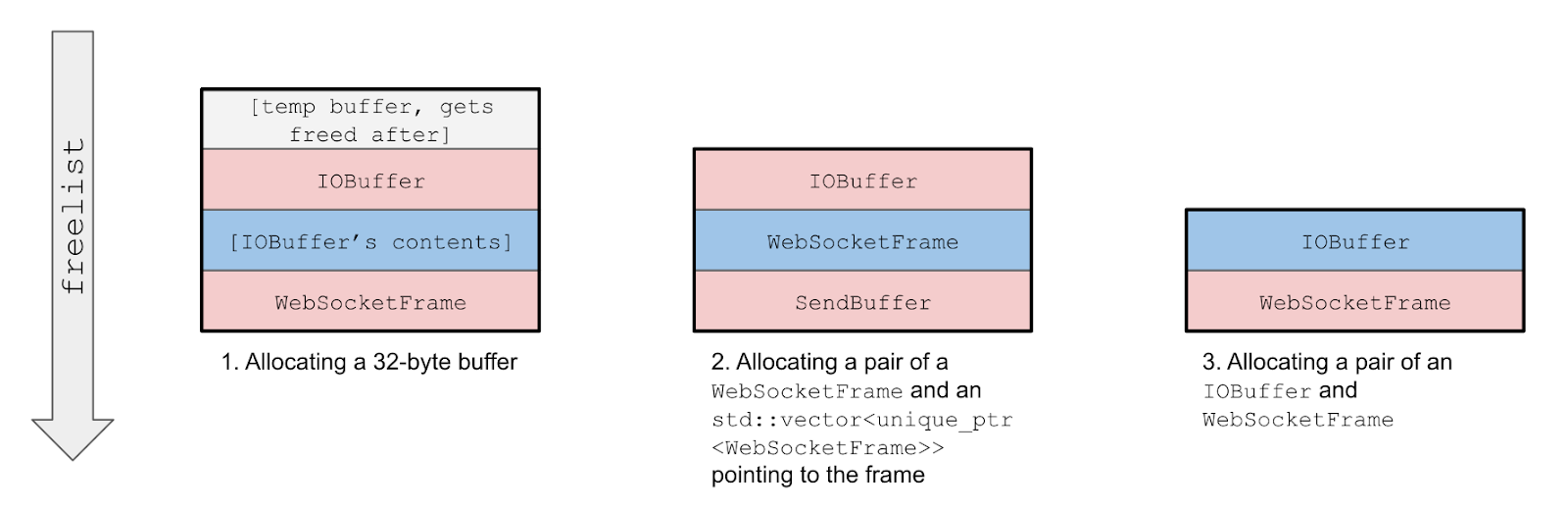
上面红色显示的对象是“多余的”分配。每一个都会对exploit的稳定性产生负面影响,但我们目前还无法避免,只能希望在无限制的重试次数下不会有太大影响。
信息泄漏
一旦我们可以相当可靠地覆盖WebSocketFrame指针,我们就将这个稍微有些恼人的原语转换为一个新的原语,它只允许我们破坏16字节bucket的对象,而允许我们从32字节bucket中释放一个分配。由于data_to_send_next_使用的是std::unique_ptr而不是scoped_refptr,所以我们也不必关心是否要创建一个假的引用计数器。这个free的fake WebSocketFrame唯一要求是它的指针必须为null。
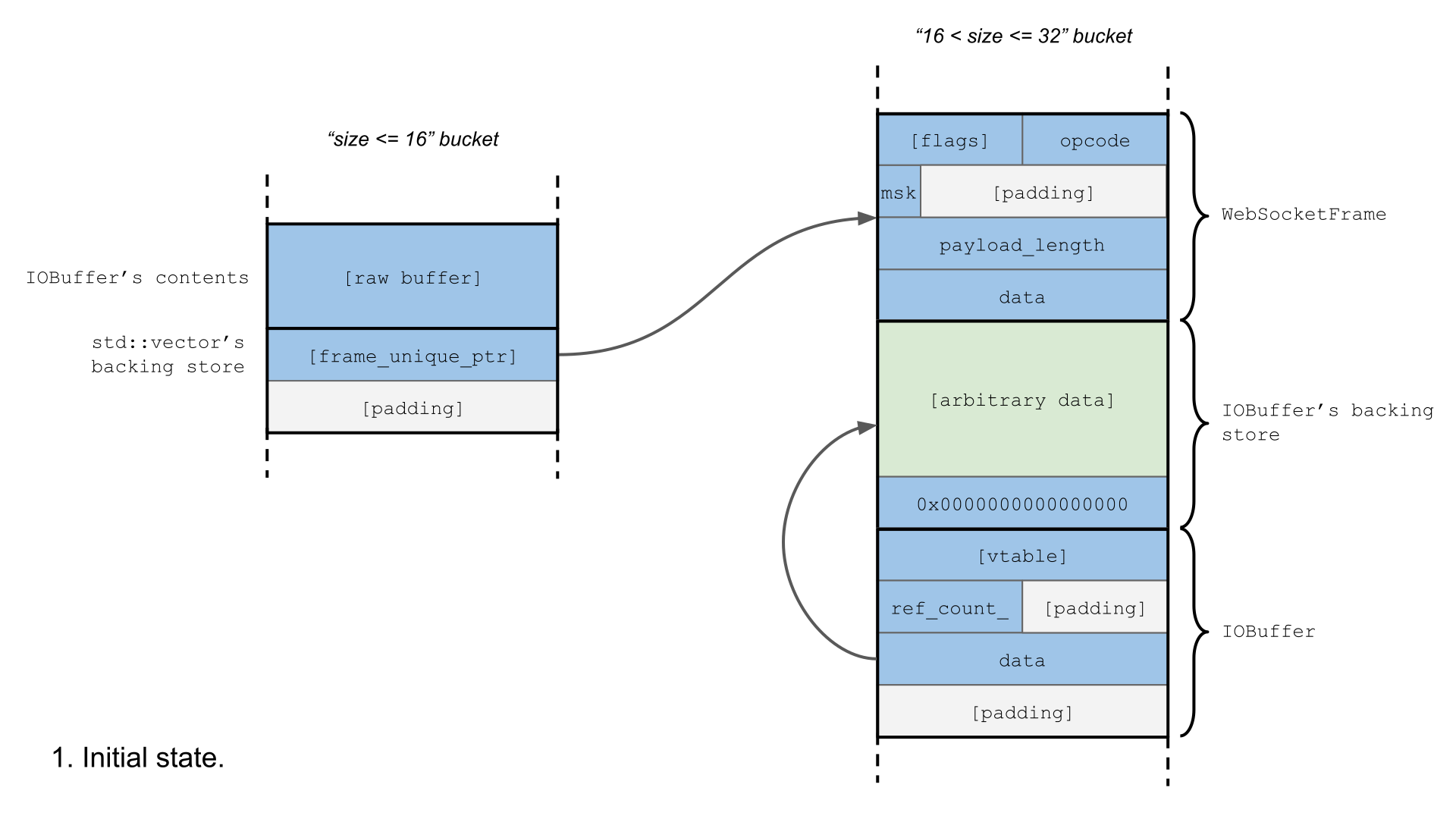
我们可以使用这个原语来构建一个非常有用的infoleak(信息泄露),它将为我们提供Chrome二进制文件在内存中的位置,以及我们可以在堆上控制的数据的位置,从而为我们提供完成exploit所需的所有信息。
在堆操作中使用WebSockets的一个优点是浏览器将把存储在这些帧中的数据发送到服务器,因此如果我们可以使用这个空闲空间来释放已经排队等待发送的IOBuffer的备份存储空间,我们将能够泄漏分配的新内容。外,由于这个size类与IOBuffer对象的分配大小相匹配,所以我们可以用一个新的IOBuffer对象替换空闲的备份存储。这将泄漏IOBuffer vtable指针,这是我们需要的第一个信息。
然而,IOBuffer对象还包含一个指向它的备份存储器的指针——这是一个大小由我们控制的堆分配。如果我们确保这是一个不会被干扰堆操作的size类,那么现在就可以泄漏这个指针,然后在exploit中释放这个分配并重用它来做更有用的事情。
代码执行
我们就快讲完了,假设我们可以重复使用泄漏分配的地址,我们知道我们可以写一些数据,我们知道应该在那里写什么数据,并且我们拥有为infoleak构建的相对强大的32字节空闲原语。
不幸的是,正如上面所提到的,我们并没有一个很好的原语来单独分配iobuffer或websocketframe;虽然对于infoleak,我们没有太多的灵活性(我们需要释放一个IOBuffer备份存储,我们需要用一个IOBuffer对象替换它),对于我们exploit的下一个阶段,我们有一些选择来尝试并增加我们成功的机会。
由于我们不再对释放IOBuffer备份存储感兴趣,我们可以将这些分配转移到一个不同大小的类中,这样我们现在就有三种不同的对象类型来自32字节的bucket:WebSocketFrame、IOBuffer和SendBuffer。如果我们能够完美地喷射,那么我们应该能够安排有3对“target IOBuffer”、“target WebSocketFrame”和“victim WebSocketFrame”。这意味着,当我们通过再次触发漏洞来破坏指向“victim WebSocketFrame”的指针时,我们有相同的几率释放IOBuffer或WebSocketFrame。
通过我们精心设计的替代对象,我们可以利用这两种可能性。我们将在调用WebSocketFrame或IOBuffer的析构函数期间获得对执行的控制。WebSocketFrame中唯一真正重要的字段是数据指针,它需要指向IOBuffer对象。因为这对应于IOBuffer对象尾部的填充字节,所以我们可以创建一个替换对象来填充释放的IOBuffer或释放的WebSocketFrame的空间。
当替换对象被释放时,如果我们替换了一个IOBuffer,那么当refcount递减为0时,我们将通过我们的fake vtable得到一个虚调用 — 如果我们替换了一个WebSocketFrame,那么WebSocketFrame将释放它的数据成员,我们已经指向另一个fake IOBuffer,这将通过我们的fake vtable再次导致一个虚调用。
在上面的所有过程中,我们一直忽略了一个小细节——由于我们之前的精心准备,这个小细节实际上是相当小的——我们需要将第二个fake IOBuffer和fake vtable存储到一个已知的内存地址中。不幸的是,由于泄漏的IOBuffer对象将被释放,因此我们无法释放之前泄漏的分配地址。
不过,这并不是一个大问题;我们可以选择让那些较大的分配进入一个“quiet”的bucket大小。如果我们预先用两个不同的websocket替换缓冲区准备bucket大小,那么我们可以释放其中一个websocket,以确保泄漏的地址与第二个websocket的缓冲区相邻。泄露地址后,我们可以释放第二个websocket,并用我们的fake对象替换相邻缓冲区的内容。

总之,我们使用已知地址的较大IOBuffer备份数据将可控数据写入内存。它包含一个fake IOBuffer vtable,以及我们的代码重用payload 和第二个伪IOBuffer。然后,我们可以再次触发该漏洞,这一次将导致IOBuffer对象或WebSocketFrame对象造成UAF,这两个对象都将使用指向更大IOBuffer备份数据的指针,这些数据现在位于已知地址。
释放破坏的对象后,我们的payload就会运行,我们的工作就完成的差不多……
概述:Component breakdown
在这一点上,我们有很多可移动的部分,所以对于那些想深入了解exploit源代码的人,这里有一个快速的细分:
- serv.py:一个自定义Web服务器,它只处理对映像文件的请求,并返回相应的响应序列以触发该漏洞。
- pywebsocket.diff:pywebsocket的几个补丁,删除了压缩并为websocket服务器设置了SO_RCVBUF。
- get_chrome_offsets.py:一个脚本,它将附加到正在运行的浏览器并收集payload所需的所有偏移量。这需要安装frida。
- CrossThreadSleep.py:实现了一个基本的可sleepable等待原语,用于sleep websocket服务器中的各个线程并从其他线程唤醒它们。
- exploit/echo_wsh.py:pywebsocket的websocket处理程序,用于处理将导致定时延迟或可唤醒延迟的多个消息类型,从而允许我们进行所需的套接字缓冲操作。。
- exploit/wake_up_wsh.py:pywebsocket的websocket处理程序,它处理多个控制消息以唤醒sleeping的“echo”套接字。
- exploit/exploit.html:用于实现exploit逻辑的javascript代码。
我们还提供了一些脚本,让读者更容易获得一个容易出现问题的Chromium版本,并正确设置其他环境:
- get_chromium.sh:检查并配置一个存在漏洞的Chromium版本的一个shell脚本。
- get_pywebsocket.sh:下载pywebsocket并为exploit服务器打补丁的一个shell脚本。
- run_pywebsocket.sh:用于启动攻击服务器的shell脚本。需要单独运行servlet.py脚本。
exploit服务器在两个端口上运行:exploit.html由websocket服务器提供,第二个服务器用于触发漏洞。
Chapter 5: 更稳定的exploit
我们有一个exploit,有时起作用。它在堆喷射期间创建了很多“无效的”分配,我们对命中正确的对象类型做了很多假设,因此让我们评估一次成功运行exploit的概率:

考虑到一次运行大约需要一分钟,即使我们几乎没有重试的次数,这绝对也不是令人满意的结果。
基于Cookie的堆修饰
为了使堆喷射更加稳定,我们需要一种方法来区分“good”和“bad”32字节分配。读者可能已经注意到,在网络进程中精确地操作堆并不是一件容易的事,特别是从一个不受破害的renderer。
HTTP cookie是我们尚未考虑的与网络相关的功能之一。出乎意料的是,网络进程不仅负责发送和接收cookie,还负责将它们存储在内存中并保存到磁盘。由于存在Cookie操作的JavaScript API,而且操作看起来并不复杂,所以我们可以使用API来构建额外的堆操作原语。
经过一些测试,我们构建了三个新的堆操作原语:

说实话,它们比我们预期的要简单得多。例如,下面是Frida脚本的输出,该脚本跟踪free_slot()方法执行期间的32字节堆状态转换,顾名思义,它只是在32字节的freelist后面附加一个新条目。

正如你所看到的,它可能不是我们想要的简单、干净、整洁的原语,但它做了我们需要它做的事情!
通过小心地将新方法集成到exploit中,我们可以消除内存区域中堆喷射所有不需要的分配。更新后的信息泄露示意图如下:
现在,在最坏的情况下,我们将用相同的值覆盖WebSocketFrame指针的LSB,这将不起作用。这给了我们7/8而不是2/8作为我们“稳定性”公式的第一个乘数。对于实施的其他部分也是如此。因此,上面的总概率应该提高到每次运行0.75。
同样,此方法有一些限制,例如:
- 在Chrome中,网站可以容纳的Cookie数量上限为180个。
- 第512个与Cookie相关的操作都会触发将内存中的Cookie存储刷新到磁盘上,这会破坏任何堆喷射。
- 每30秒自动刷新一次。
- 我们网站的cookie存储应该在每次运行spray之前处于特定状态,否则操作方法可能会产生不稳定的结果。
幸运的是,我们的exploit设计可以自动处理上述大多数限制。堆喷射必须分成小块,但可以单独处理。因此,由于我们已经达到了WebSocket最大已连接数量相关的喷射大小的限制,实际的exploit最终变得不那么稳定。然而,再加上重新启动网络进程的功能,似乎在成功之前通常只需要2-3次尝试,这比之前的版本要好得多。
Chapter 3: 结论
Chrome所做的服务化工作对这种bug的开发产生了一些不错的影响。首先,将这段代码移动到一个独立的服务进程(网络服务)中对查找稳定的堆修饰原语的难度有很大的影响。这意味着,即使没有适当的沙盒,Chrome中的网络服务实现也使现在的网络堆栈比之前更难利用了!实现相对较少的服务进程与较大的独立组件相比,本质上是更难以利用的目标;它们减少了可用的机器数量,这减少了攻击者的选择。我们没有考虑到这一点,所以这是一个非常不错的惊喜。
其次,重新启动服务进程有助于开发。对于exploit开发人员来说,知道可以进行任意尝试可以减轻很多压力,有更多的自由去创建和使用不稳定的原语。在没有随机化的进程平台上更是如此,我们选择Linux是为了构建一个稳定的信息泄漏,在其他平台上利用可能更容易。
考虑到额外的复杂性和稳定性问题,这类bug目前不太可能被攻击者使用。renderer bug和 OS/kernel 特权提升的“传统”浏览器开发链更易于编写和维护。
但是,如果这些链开始变得稀少,攻击者可能会转移到这种漏洞上,这种想法并不是不现实的,我们已经证明了这种问题是可能的。这意味着即使这些不太常见的攻击,沙盒检查对于浏览器的整体安全性也很重要。