
0x5 CVE-2020-13933
0x5.1 漏洞简介
影响版本: shiro<1.6.0
类型: 权限绕过
其他信息:
这个洞跟CVE-2020-11989有点相似的地方就是就是利用URL解码的差异性来实现绕过。
CVE-2020-13933:Apache Shiro 权限绕过漏洞分析
0x5.2 漏洞配置
这个洞是不会受到Spring的版本限制的。
<dependency>
<groupId>org.apache.shiro</groupId>
<artifactId>shiro-web</artifactId>
<version>1.5.3</version>
</dependency>
<dependency>
<groupId>org.apache.shiro</groupId>
<artifactId>shiro-spring</artifactId>
<version>1.5.3</version>
</dependency>
Shiro配置,这个洞也是有限制的只能是ant的风格为单*号才可以:
map.put("/hello/*", "authc");
@ResponseBody
@RequestMapping(value="/hello" +
"" +
"/{index}", method= RequestMethod.GET)
public String hello1(@PathVariable String index){
return "Hello World"+ index.toString() + "!";
}
0x5.3 漏洞演示

访问302,然后poc:
/hello/%3bluanxie
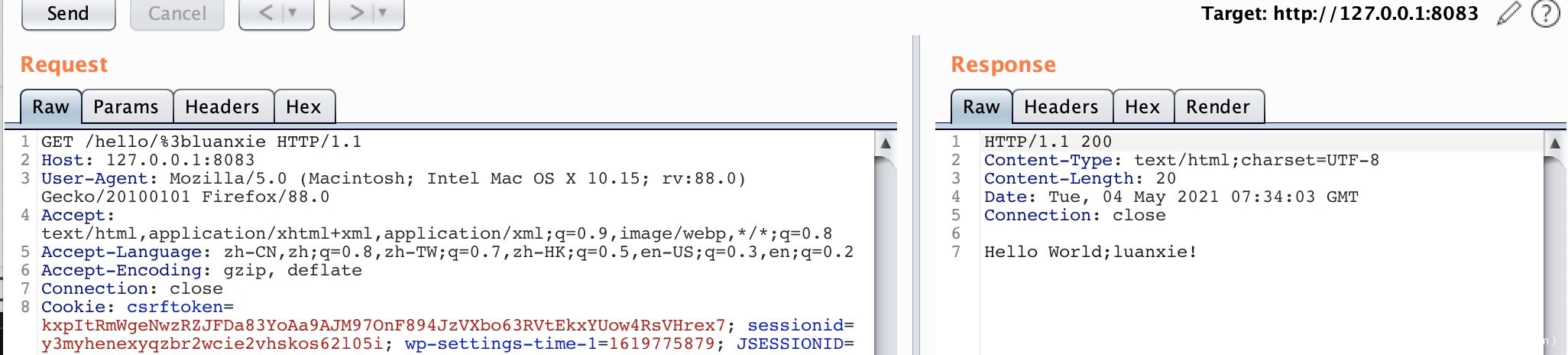
看到这个POC的时候,我当时就觉得我前面分析两个洞的时候,是不是漏了什么关键点没去分析。
然后最让我头疼的的是,为什么需要对;要编码才能利用成功,下面我们通过分析来复盘我们前两次学习过程出现的问题。
0x5.4 漏洞分析
断点依然是在上一次的修补点:
org.apache.shiro.web.util.WebUtils#getPathWithinApplication

这里我们逐步跟进去,上一次我没跟removeSemicolon, 因为从函数名这个其实就是Shiro一直以来的操作,就是去除;号后面的内容,然后normalize,这个并没有很大问题。
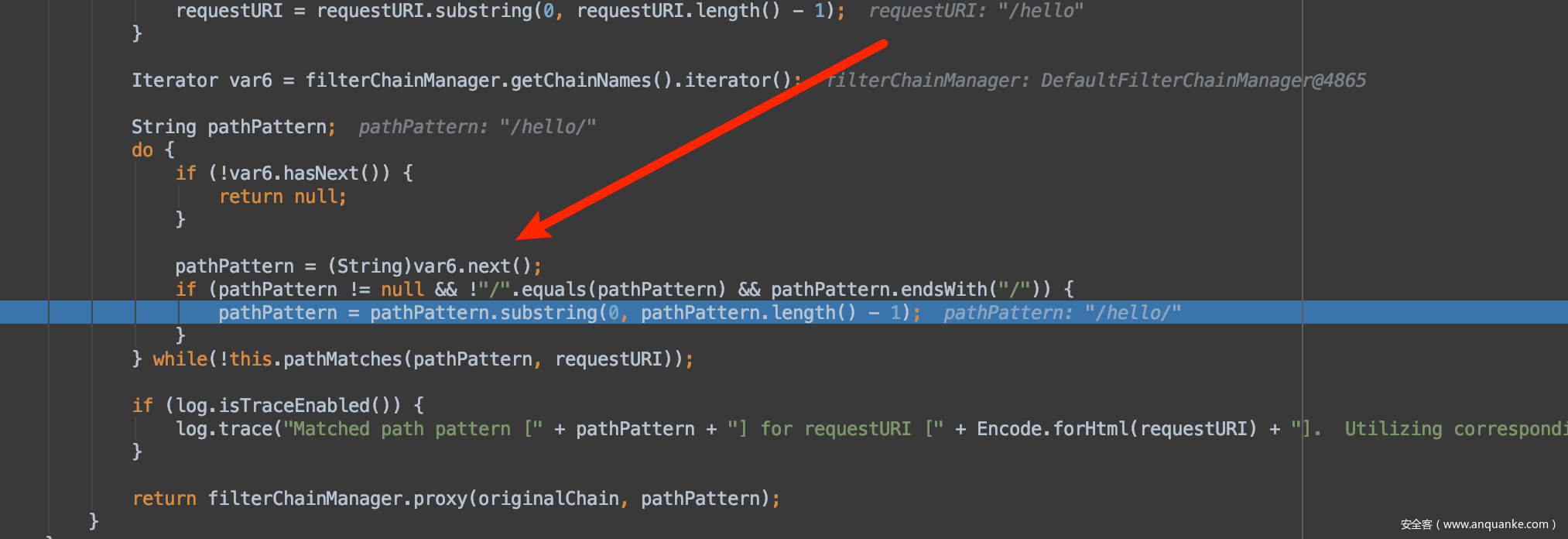
然后函数返回的结果是这个:

本来应该获取到uri的是/hello/,然后因为最早的那个shiro-682的洞,所以会执行去掉末尾的斜杆。
if (requestURI != null && !"/".equals(requestURI) && requestURI.endsWith("/")) {
requestURI = requestURI.substring(0, requestURI.length() - 1);
}
变成了:/hello
首先通过,Iterator var6 = filterChainManager.getChainNames().iterator()获取了我们定义的filter,进入do循环逐个取值给pathPattern
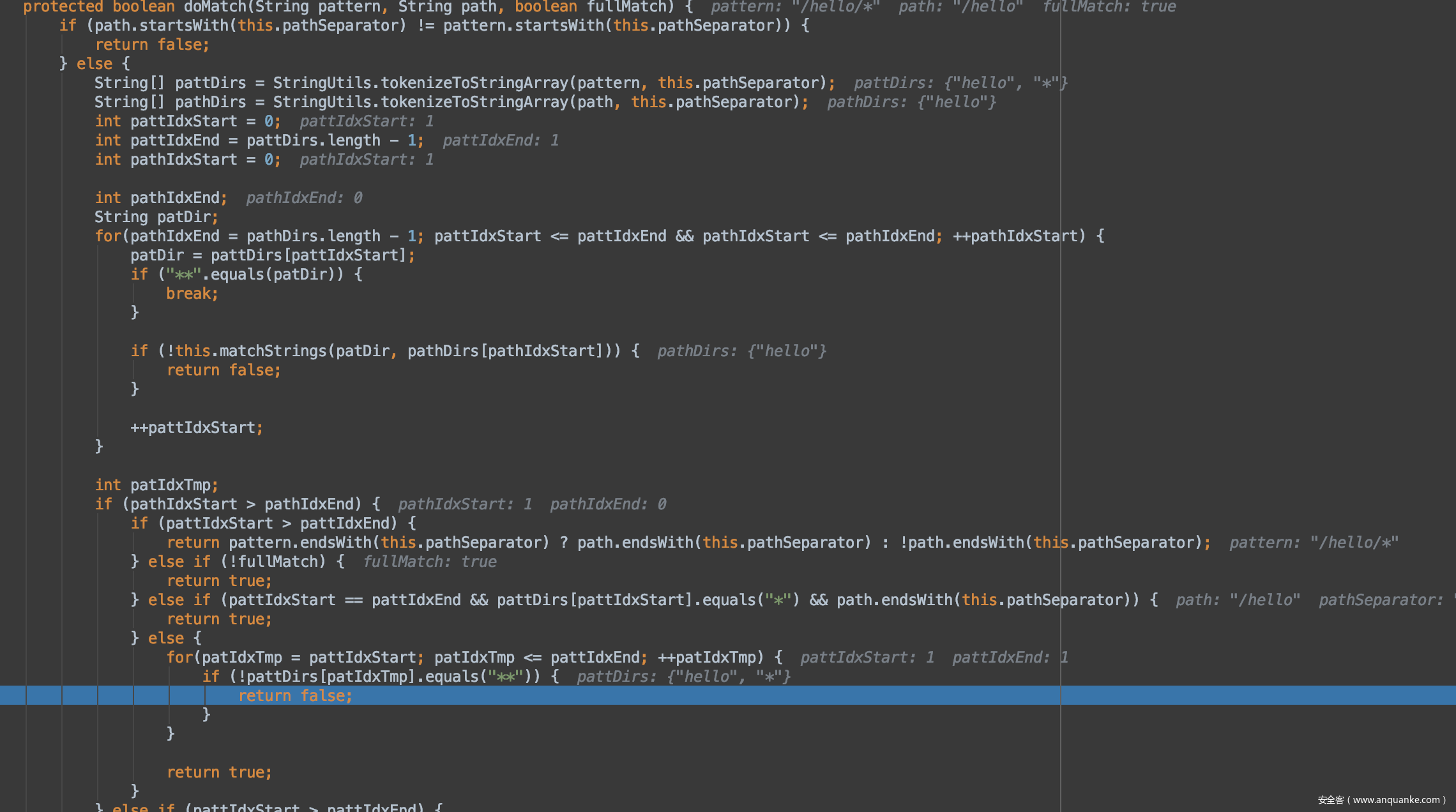
其实都没必要去看这个算法怎么做匹配的,因为/hello/*本来就不会匹配/hello,
那么这样,如果是这样呢,map.put("/hello/", "authc");,emm,在取出来进行匹配的时候,
就会被去掉/,那么我来多几个呗。
map.put("/hello//", "authc");
稍微绕过了
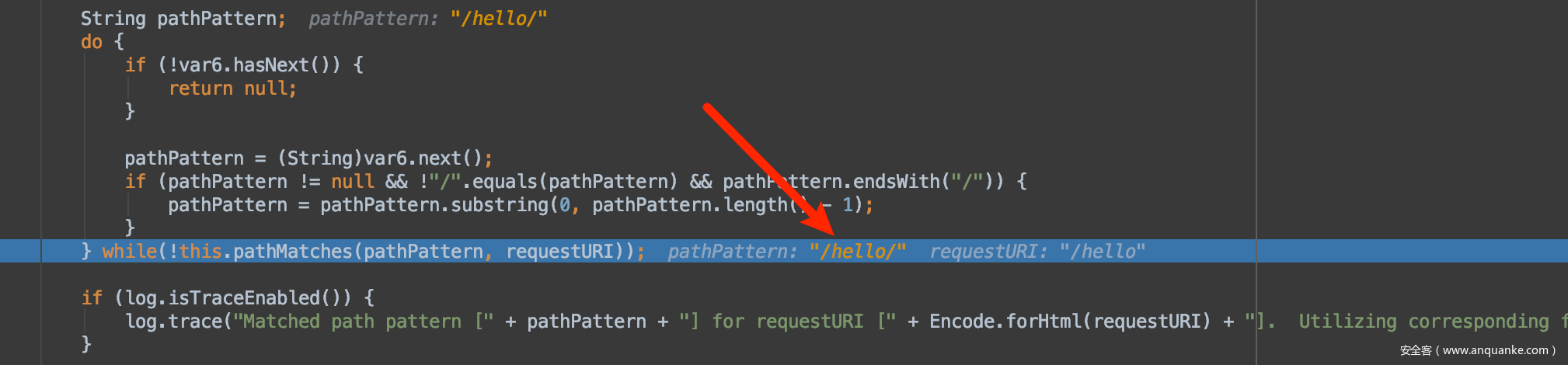
这个时候我们就可以回头去读一下Shiro的匹配算法了。
首先是如果
pattern和path开头不一样直接false然后就是
StringUtils.tokenizeToStringArray分割字符串得到数组然后一个循环,比较,如果出现某数组字符串不匹配,除开
**就会返回false只要没有
**出现的话,且字符串数组=1,就没那么复杂的解析过程,直接返回pattern.endsWith(this.pathSeparator) ? path.endsWith(this.pathSeparator) : !path.endsWith(this.pathSeparator);如果pattern是以/结尾的话,那么是 True,返回
path.endsWith(this.pathSeparator),这个时候path不是以/结尾的,所以最终也不匹配。如果是
/*的话,字符串数组>1,那么最终会进入
这个过程说明,
/hello/*可以匹配/hello/,但是没办法匹配到/hello,然后shiro又做了去除/处理,emmm,根本不可能构造出/hello/,构造出来也没啥可用的但是如果是,
/hello/**,这里就不返回false,直接跳到下面了,最终会返回True,没办法绕过。说明/hello/**可以匹配到/hello
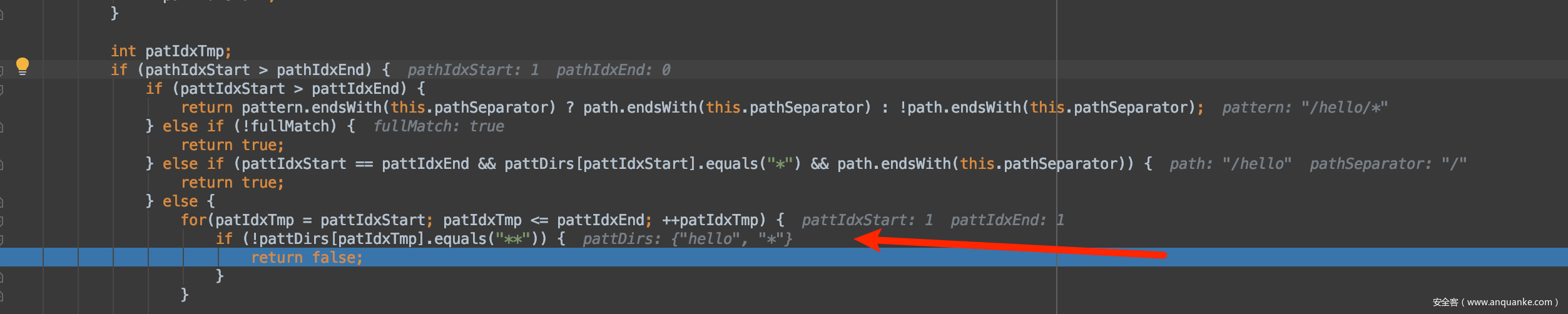
其实来到这里我们就明白了,第一步通过%3b解码成;,然后以前的洞删掉了/,导致了bypass Shiro。
如果我们不用%3b,而是直接
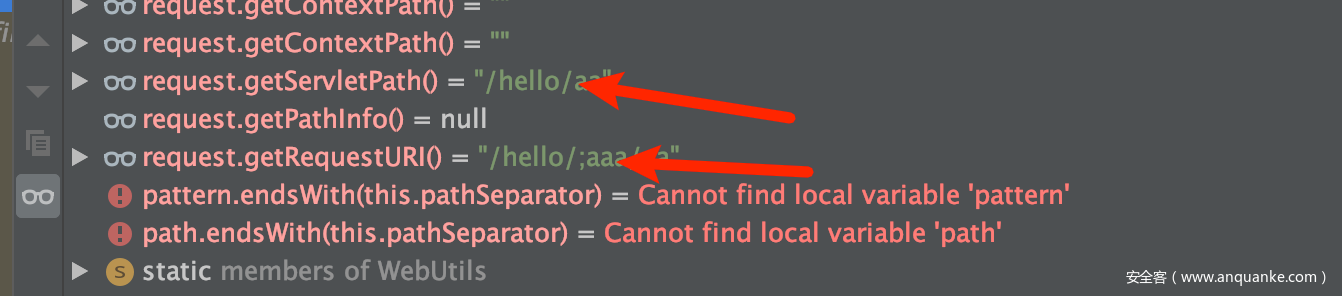
那么;直接会被request.getServletPath()处理掉,从而变成了/hello/aa,被/hello/**这种ant所匹配,导致第一层都没办法绕过。(这个其实就是cve2020-1957的绕过思路呀!肯定是没办法的呀)
0x5.5 漏洞修复
说实话,关于这个洞,我当时思考的修复方式是,好像只能是去屏蔽%3b这个字符了,感觉真的很无奈。
diff:https://github.com/apache/shiro/compare/shiro-root-1.5.3…shiro-root-1.6.0
发现确实新增InvalidRequestFilter.java,但是具体作用不知道在哪里起的,
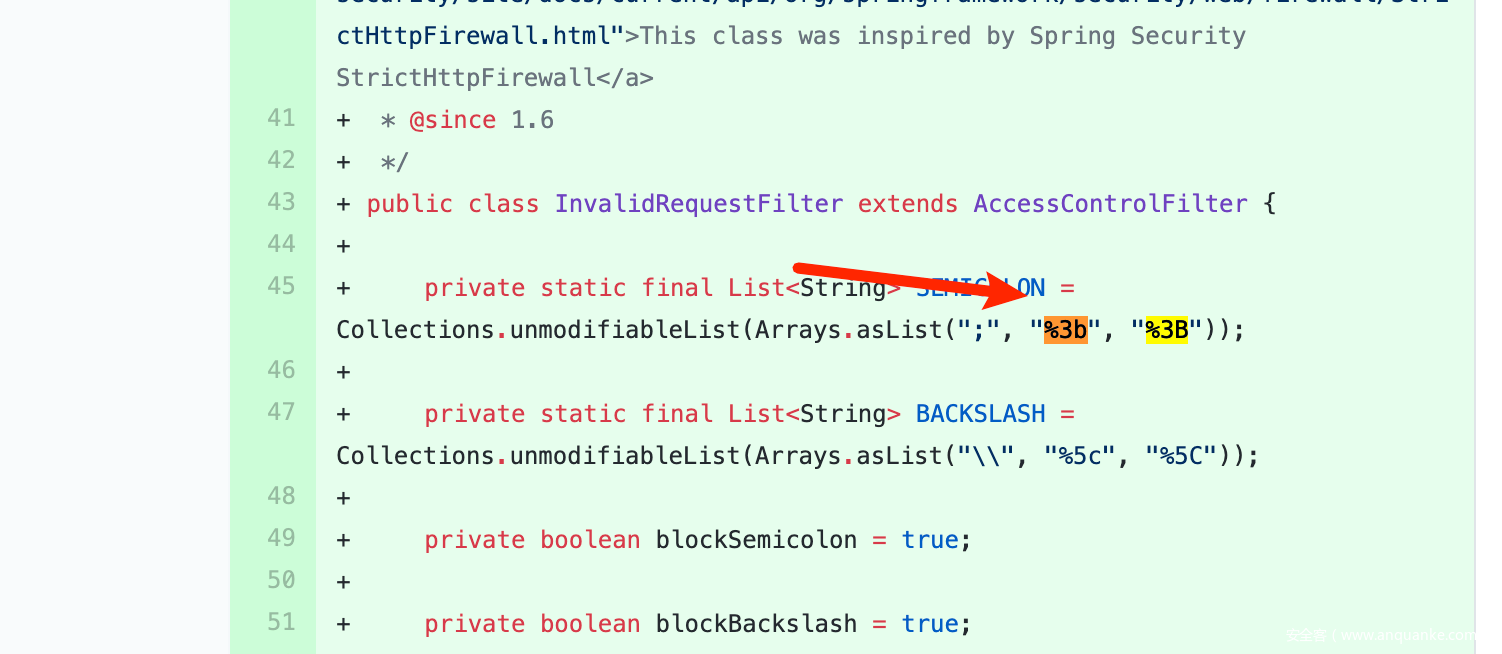
然后在这个文件被调用:
support/spring/src/main/java/org/apache/shiro/spring/web/ShiroFilterFactoryBean.java
这个文件新增了一个/**匹配没有设置filter类型,用于解决失配的时候还是可以调用默认的过滤器

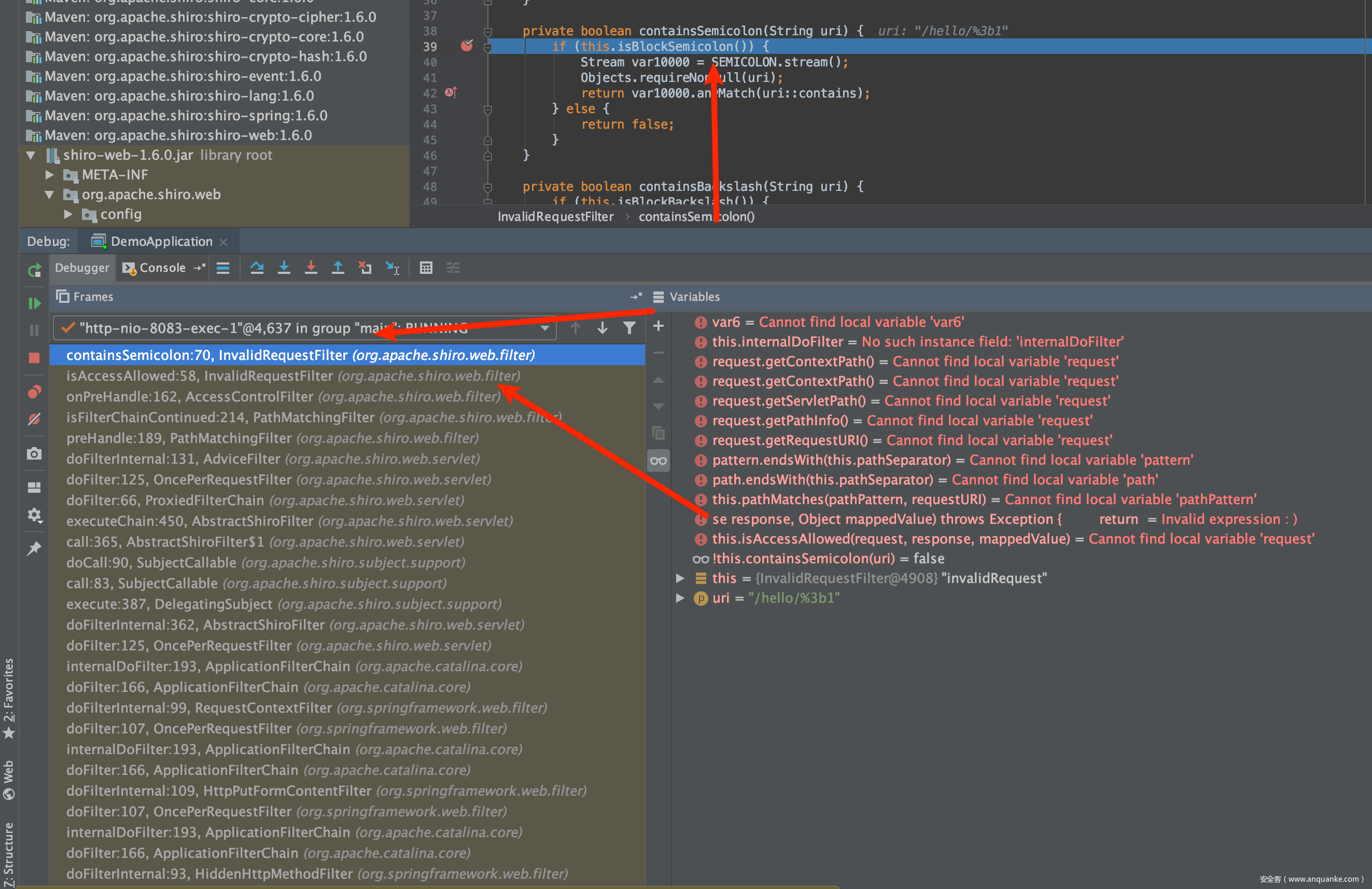
然后输入特殊字符的时候,过滤器会进行过滤,关于是如何进行过滤的,值得详细写一篇文章,这里我们只要知道它的修复方式,是做了特殊字符,存在就抛出400就行了。
return !this.containsSemicolon(uri) && !this.containsBackslash(uri) && !this.containsNonAsciiCharacters(uri);
0x6 CVE-2020-17510
0x6.1 漏洞简介
影响版本: shiro<1.7.0
类型: 权限绕过
其他信息:
中风险,需结合Spring使用环境,危害偏低一点
0x6.5 漏洞分析
diff:https://github.com/apache/shiro/compare/shiro-root-1.6.0…shiro-root-1.7.0
改动:

这个洞我发现他增加了request.getPathInfo的方式检测字符,而在Spring-boot默认这个值是空,但是在其他情况,这个值可控的话,我们可以在这里插入;和..实现绕过,结合前面的分析,可以知道URI是由request.getServletPath + request.getPathInfo得到的,所以是可以去绕过的,不过由于这个洞鲜少人讨论,作者也没去公开,这个利用方式研究价值很低,笔者对此没有很大兴趣,所以就没去折腾场景来利用, 欢迎其他师傅感兴趣地话继续研究。
0x7 CVE-2020-17523
0x7.1 漏洞简介
影响版本: shiro<1.7.0
类型: 权限绕过
其他信息:当Apache Shiro与Spring框架结合使用时,在一定权限匹配规则下,攻击者可通过构造特殊的 HTTP 请求包绕过身份认证。
0x7.2 漏洞配置
<dependency>
<groupId>org.apache.shiro</groupId>
<artifactId>shiro-web</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.shiro</groupId>
<artifactId>shiro-spring</artifactId>
<version>1.6.0</version>
</dependency>
这个漏洞我建议spring-boot用2.4.5的,这个版本默认会开启全路径匹配模式。
当Spring Boot版本在小于等于2.3.0.RELEASE的情况下,
alwaysUseFullPath为默认值false,这会使得其获取ServletPath,所以在路由匹配时相当于会进行路径标准化包括对%2e解码以及处理跨目录,这可能导致身份验证绕过。而反过来由于高版本将alwaysUseFullPath自动配置成了true从而开启全路径,又可能导致一些安全问题
0x7.3 漏洞演示
通杀版本:/hello/%20

高版本默认支持:/hello/%2e/ 或者 /hello/%2e

其实这个洞,基于之前的%3B实现绕过的思路,其实很容易想到去Fuzz下的,看看除了%3B是不是还有其他字符可以在Shiro中造成失配,而Spring-boot可以正常匹配的,都不用去分析具体代码的,就可以拿到的一个ByPass。
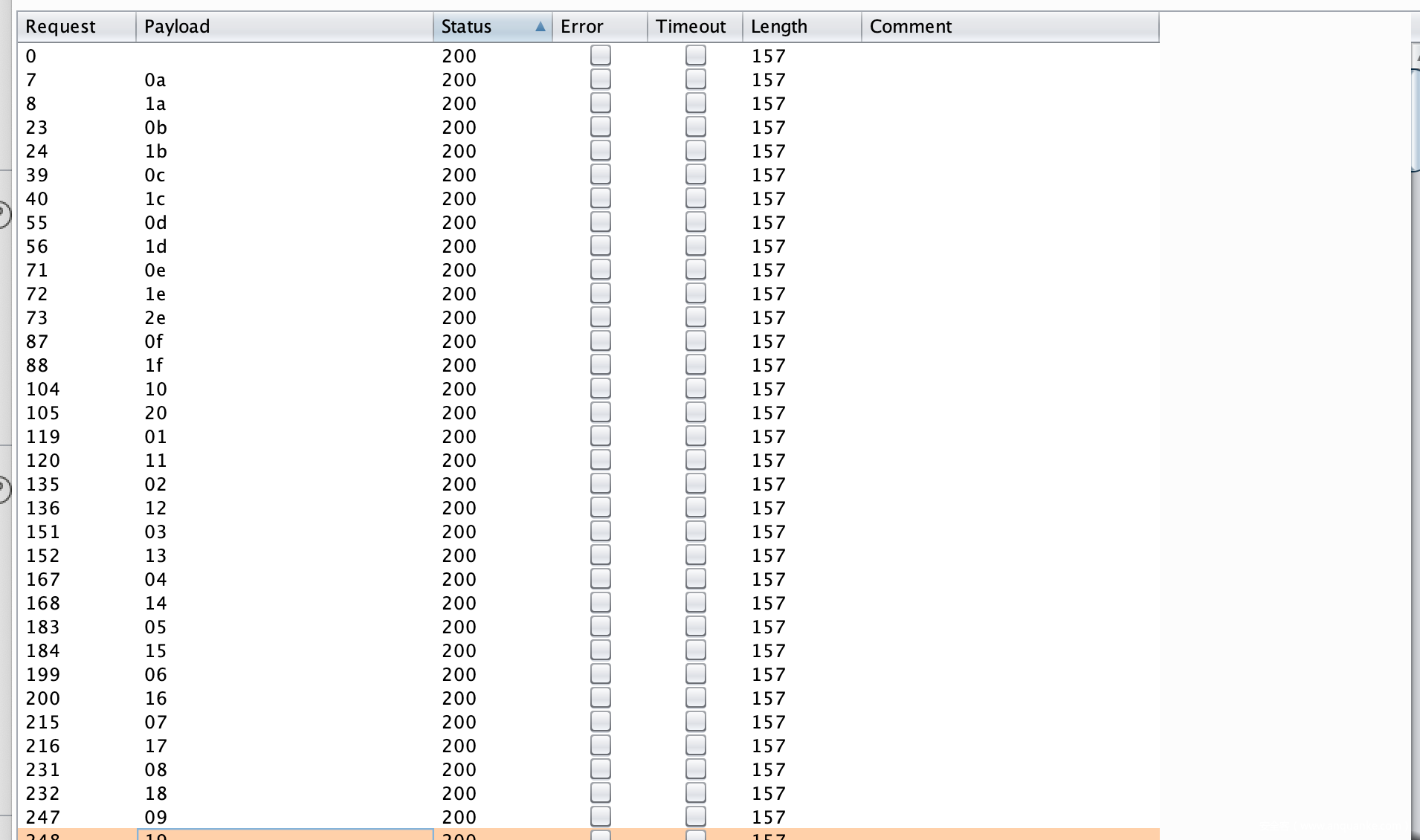
但是这两种绕过方式其实非常不同的,出现在了两个不同地方的错误处理方式。
0x7.4 漏洞分析
第一种绕过方式分析:
断点打在org.apache.shiro.web.util.WebUtils#getPathWithinApplication
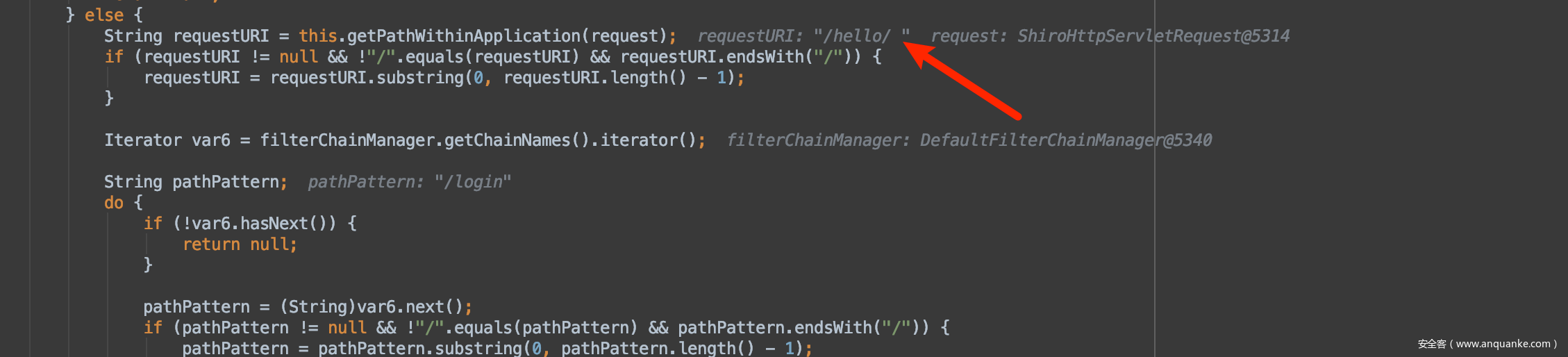
这里处理结果和前面一样,解码了所以变成了空格。
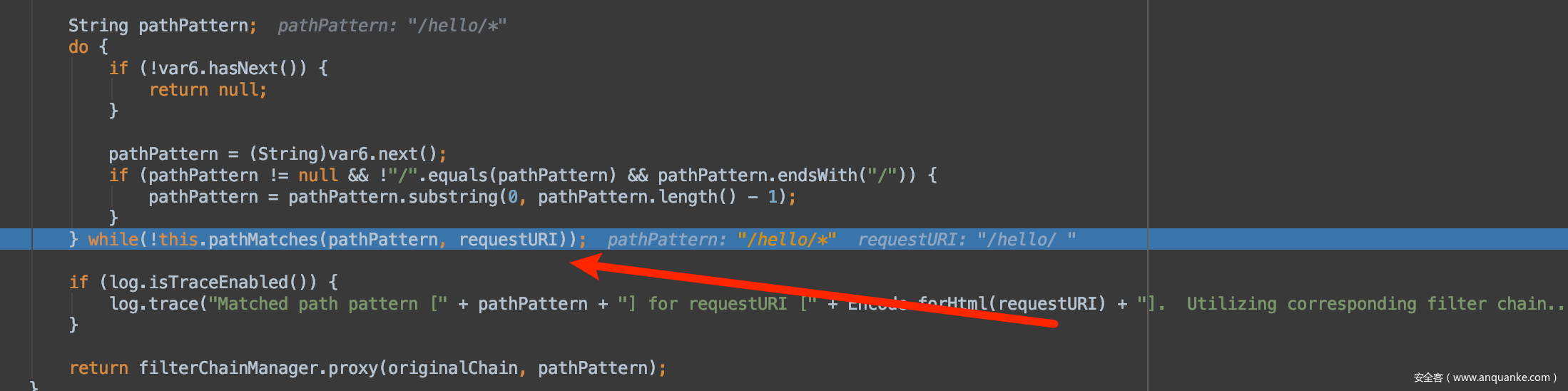
跟进这里看匹配,
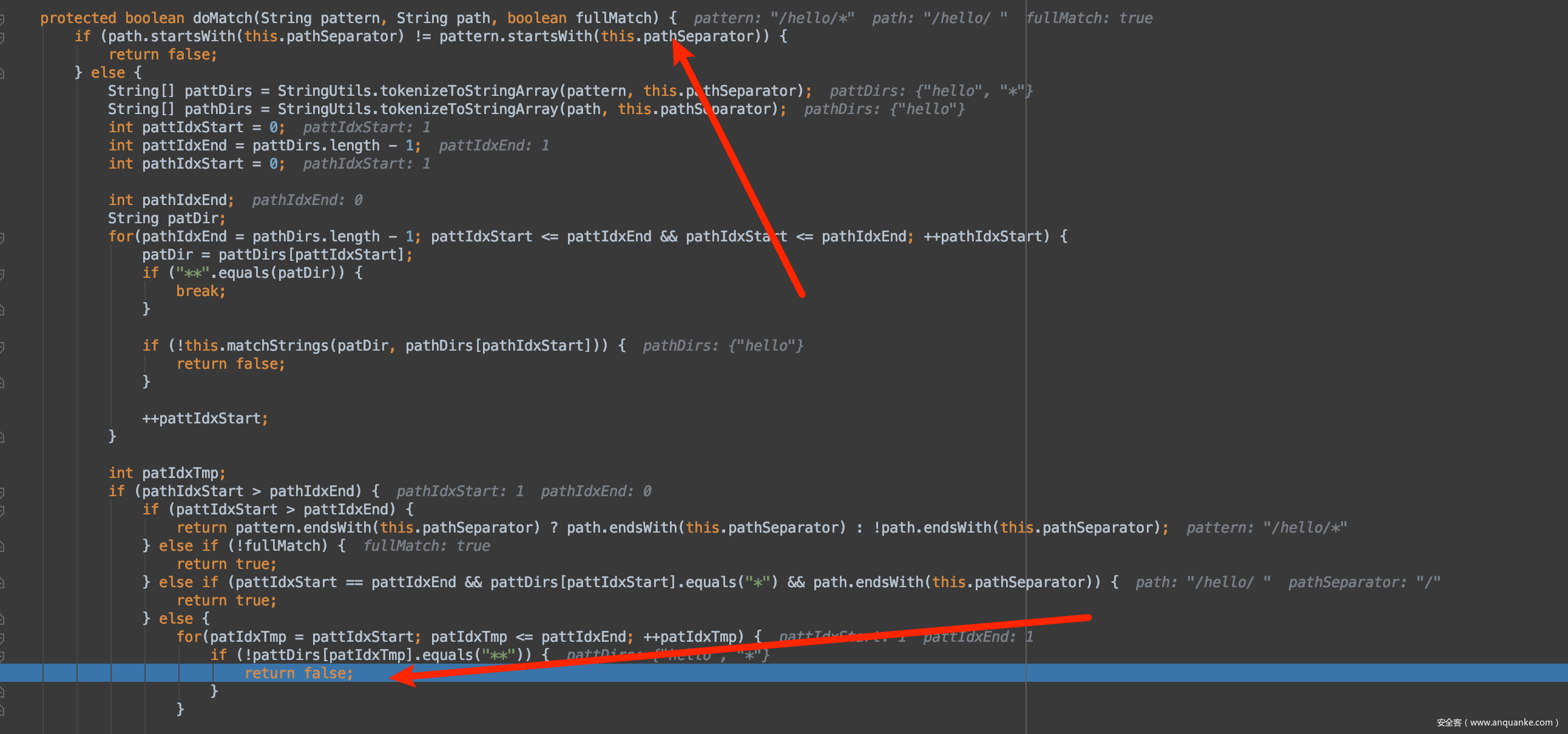
很明显,这里和上次分析结果是一样的,最终还是因为*返回了false,否则True。
那么为什么会这样呢? 那为什么/hello/aa这样就不行呢? 其实就是StringUtils.tokenizeToStringArray没有正确分割字符串导致的? %20 应该是被当做空字符了,导致分割的数组长度=1,就会进入那个return false.

所以这里成功Bypass了Shiro的检测,最后让我们来看下Spring-boot是怎么处理的
断点:org.springframework.web.servlet.DispatcherServlet#doDispatch
逐步跟到:org.springframework.web.servlet.handler.AbstractHandlerMethodMapping#lookupHandlerMethod

这里是根据lookpath进行匹配,没有直接被找到

下面进入用RequestMapping注册的列表来匹配:

这里继续进入匹配:


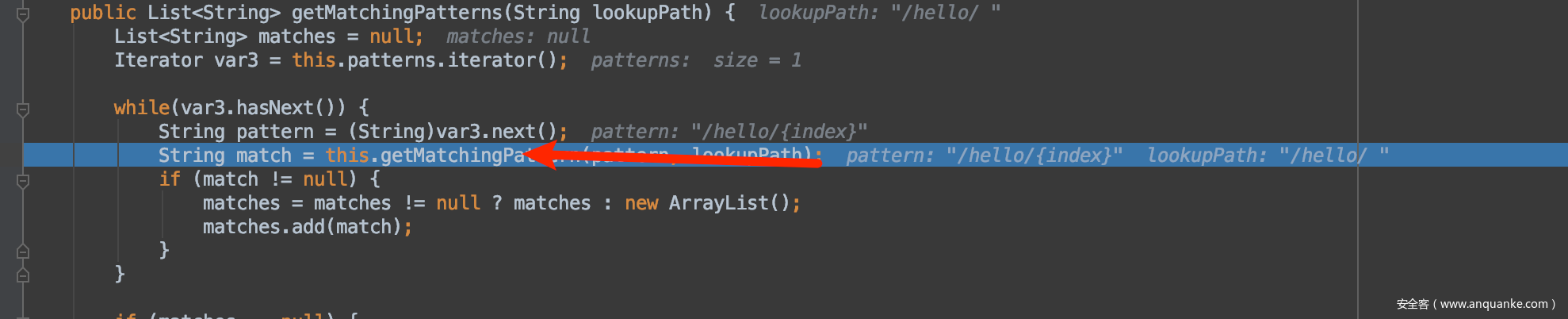
最终这个org.springframework.util.AntPathMatcher#doMatch进行了解析,和之前算法差不多,但是
this.tokenizePath(path)返回的结果是2包括%20,所以可以匹配成功,最终解析到了/hello/{index}
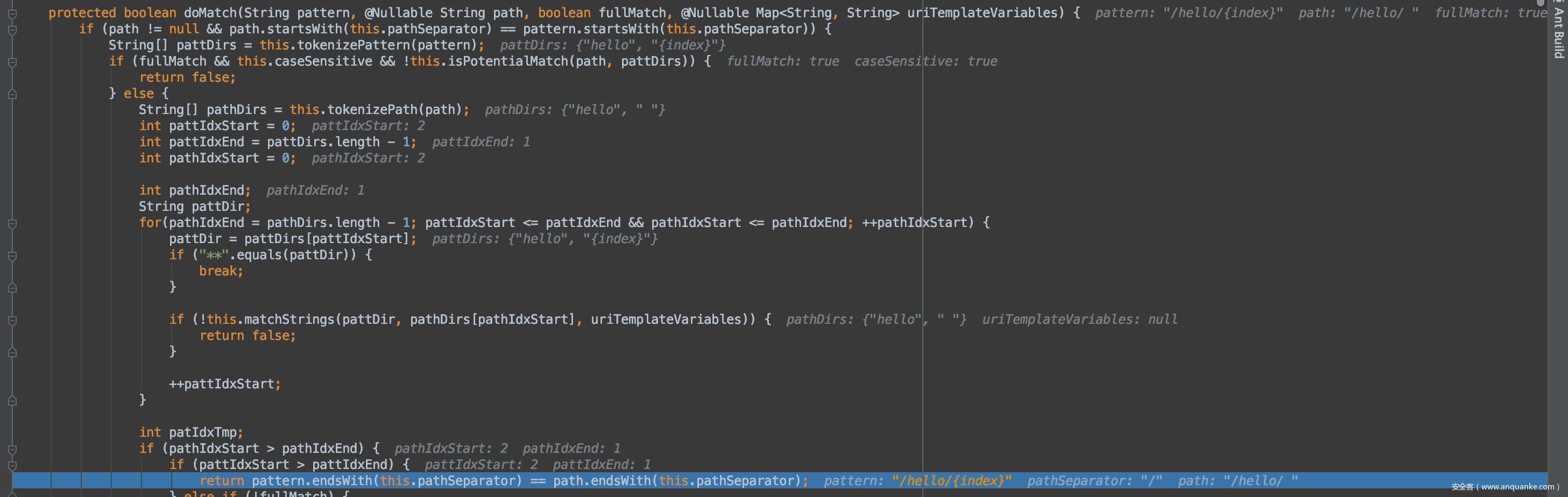
第二种绕过方式分析:
这个其实在分析cve-2020-13933的时候,我就考虑过这种方式去绕过(部分原理相同,利用默认去掉/造成的失配),然后当时实践了,由于采取了低版本的spring-boot,默认没开启全路径匹配模式,导致我当时没成功。
首先说一下网上有些文章,分析的时候不够全面,但是又概括性总结了原因,有一定的误导,这里我列出我的debug结果
/hello/%2e->request.getServletPath()->/hello/
/hello/%2e/->request.getServletPath()->urldecode->/helo/
/hello/%2e%2e ->request.getServletPath() -> urldecode->/
也就是说,request.getServletPath()针对%2e会先解码,然后对此进行处理。
所以洞出现的问题是:
request.getServletPath() 处理这种URL时候会返回/hello/,然后shiro默认会去掉最后/,然后再进行匹配,导致了绕过。
0x7.5 漏洞修复
diff:https://github.com/apache/shiro/compare/shiro-root-1.7.0…shiro-root-1.7.1

这个处理就可以避免空白字符没被正确分割出来的问题,解决了第一种绕过问题。
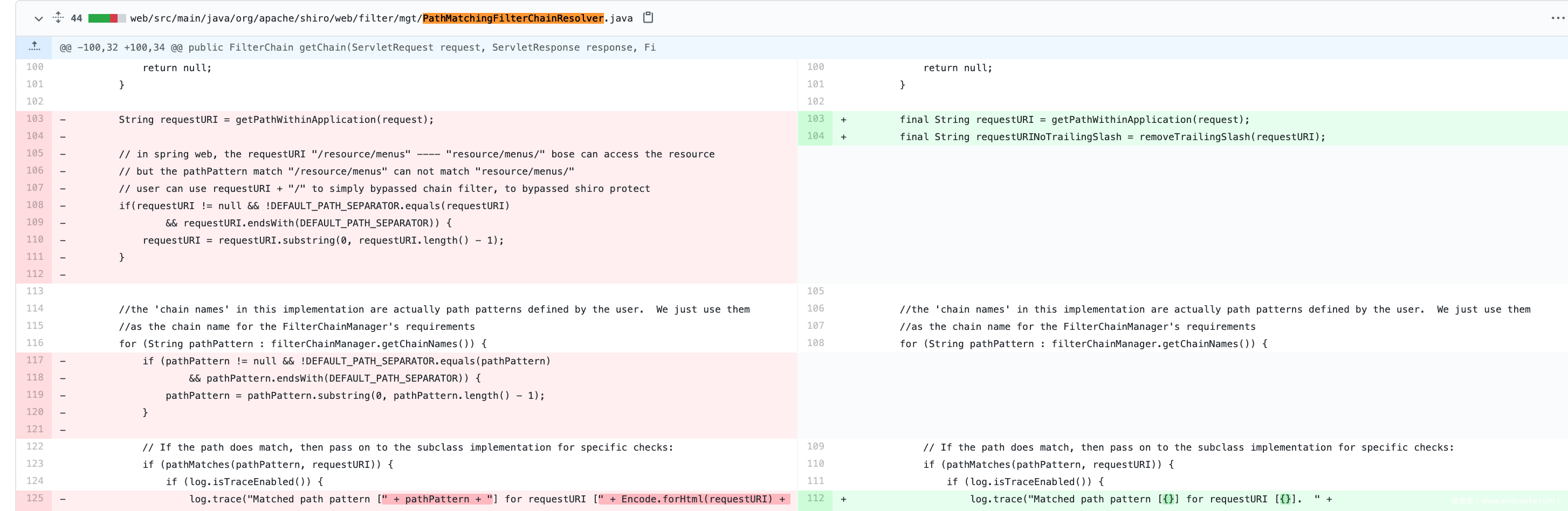
然后可以看到这里为了避免%2e,这里首先去掉了之前shiro-682,为了修补末尾/绕过问题,做的一个去掉默认路径/的操作。
然后后面写了个if/else的判断

先不去掉/来做匹配,如果匹配失败,在考虑去掉/,这样考虑是基于以前的问题和现在的问题共同考虑
首先以前是 /hello被/hello/实现了绕过,那么在做匹配的时候,那么第一次匹配失败,然后进入了第二个去掉/匹配成功
现在是/hello/*被先/hello/默认去掉/->/hello实现了绕过,那么在做匹配的时候,第一次先保留/hello/可以成功被/hello/*匹配。
0x8 总结
漏洞的最基本原理,通俗来说就是,一个原始恶意构造地URL ,首先要绕过Shiro的判断,然后被Spring解析到最终的函数,也就是Shiro解析URL和Spring解析URL的差异性。然后多次Bypass都是针对实现解析的环节存在一些问题导致。
行文颇长,若有不当之处,多多包涵。