
在对嵌入式设备进行逆向分析的过程中,偶尔会遇到一些比较小众或专业性较强的处理器,使用ida默认不支持的指令集。这时为了愉快的使用ida pro逆向就需要编写对应的处理器模块。出于学习目的,找一个非常简单的指令集来探路,CHIP-8再合适不过了。
CHIP-8简介
CHIP-8是一种解释型编程语言,出现在上世纪七十年代中期,被用来开发电子游戏以及图形化计算器等。CHIP-8的代码运行在CHIP-8虚拟机上。
- 多数时候其解释器需要占据内存空间的前512个字节,所以程序通常加载在0x200处,且不会用到前512字节地址。
- CHIP-8使用16个8bit的数据寄存器,命名为V0-VF。其中VF寄存器在执行某些指令时作为状态寄存器。有一个16位的地址寄存器I。
- CHIP-8有两个定时器,延时寄存器(Delay timer)与声音寄存器(Sound timer)。
- 唯一使用栈的地方是call的时候存储返回地址其他信息可以在wikipedia上了解:https://en.wikipedia.org/wiki/CHIP-8
初探ida处理器模块(IDA Pro 7.0)
ida处理器模块的样例可以在sdk中modules目录下找到,一打开目录映入眼帘的就是许多的c++写的处理器模块。在module/script下有三个python的处理器模块,包含一个proctemplate.py模板。这里选择使用python编写,在模板文件中可以看到主要代码为PROCESSOR_ENTRY方法返回一个继承自processor_t的sample_proccesst,类中有许多的notify开头的回调方法,每个都有少量对其应该负责的工作的注释。 通过注释可以知道其中notify_emu``notify_out_operand notify_out_insn notify_ana几个方法是强制性的。
IDA指令解析流程
分析(Ana)
在notify_ana(self, insn)中,需要做的是读取数据并解析成指令。根据opcode找到对应的指令,读取并设置好指令的参数与属性。其中insn为一个insn_t类型的变量,即为要设置的指令对象。调用insn.get_next_byte()系列方法可以获取到当前的数据,也就是下一步要解析的指令或操作数。设置insn的itype属性为指令的itype,根据操作数数量设置insn.Op1及insn.Op2的系列属性如type(操作数类型):o_imm(立即数)/o_reg(寄存器)/o_mem(内存)……、dtype(操作数大小):dt_byte/dt_word/dt_dword和value(操作数的值)。
模拟(Emu)
体现在notify_emu(self)中,用于设置数据与代码之间的关系,例如当前指令执行完毕后如果顺序执行下一条指令就要通过add_cref(insn.ea, insn.ea + insn.size, fl_F)来告诉ida这条指令的下一条在哪。其中第一个参数为出发点,多数时候为当前指令地址,第二个参数为将跳到的地址,第三个参数有可能为 fl_F(顺序),fl_JN/fl_JF(跳转)以及fl_CN/fl_CF(调用)。以及使用add_dref(op.addr, op.offb, dr_O)类似指令来添加数据的引用信息。如果有对栈数据的分析也在模拟过程中处理,可参考ebc.py中emu回调所调用的trace_sp方法。再笔者的理解中,除了个别情况,大多数修改ida数据库中数据的操作都在模拟部分进行。
输出(output)
体现在notify_out_operand(self, ctx, op)与notify_out_insn(self, ctx)两个方法。notify_out_operand用来输出参数,notify_out_insn用来输出指令。注释中特意指出在这两个方法中不应该有任何操作数据库,修改标志位等操作。笔者认为与output操作执行次数较多有关。
看一看script.dll
在ida的procs目录下可以看到script.dll与script64.dll两个文件,其与我们使用python编写处理器模块密切相关。用ida打开script.dll,字符串中可以看到许多在proctemplate.py模板中出现过的熟悉的方法名。初始化过程中sub_130021F0=>sub_13005B30=>sub_13006100会寻找PROCESSOR_ENTRY方法并尝试接收其返回的对象
char __fastcall sub_13006100(__int64 a1, __int64 a2, _BYTE *a3, __int64 a4)
{
_QWORD *v4; // rbx
_BYTE *v5; // rsi
unsigned __int8 (__fastcall *v6)(_BYTE *, __int64, _QWORD *); // r9
__int64 v7; // rdi
v4 = (_QWORD *)a4;
v5 = a3;
v6 = *(unsigned __int8 (__fastcall **)(_BYTE *, __int64, _QWORD *))(a1 + 112);
v7 = a1;
if ( v6 )
{
if ( !v6(a3, a2, v4) )
return 0;
}
else
{
if ( !(*(unsigned __int8 (__fastcall **)(__int64, _QWORD *))(a1 + 48))(a2, v4) )
return 0;
if ( !(*(unsigned __int8 (__fastcall **)(_QWORD, _QWORD, const char *))(v7 + 88))(0i64, 0i64, "PROCESSOR_ENTRY") )
{
sub_13003EA0(v4, "PROCESSOR_ENTRY attribute was not found");
return 0;
}
if ( !(*(unsigned __int8 (__fastcall **)(_BYTE *, const char *, _QWORD, _QWORD, _QWORD *))(v7 + 56))(
v5,
"PROCESSOR_ENTRY",
0i64,
0i64,
v4) )
return 0;
}
if ( *v5 == 5 )
return 1;
sub_13003EA0(v4, "should return an object!");
return 0;
}
成功后在sub_13003F70中检查前文提到的几个强制性的回调函数是否存在
do
{
if ( !(unsigned __int8)sub_13005FD0(off_1300ABE8[v2], &unk_1300F150) )
{
sub_13005260(v1, "Processor module script: missing callback '%s'", off_1300ABE8[v2]);
return 0;
}
++v2;
}
while ( v2 < 4 );
随后会在sub_13004C90中解析几个处理器属性,可以注意到assembler与instruc,也是一会必须要编写好的属性。
__int64 __fastcall sub_13004C90(__int64 a1, __int64 a2, __int64 a3, __int64 a4)
{
__int64 v4; // rbx
unsigned __int8 v5; // si
int v6; // eax
__int64 v7; // rdx
__int64 v8; // r8
size_t v9; // rbx
unsigned __int64 v10; // rdi
__int64 v11; // rax
char *v12; // rax
char *v13; // rcx
__int64 v14; // r8
__int64 v15; // r8
__int64 v16; // r8
char v18; // [rsp+20h] [rbp-448h]
int v19; // [rsp+28h] [rbp-440h]
__int64 v20; // [rsp+40h] [rbp-428h]
char Src[1024]; // [rsp+50h] [rbp-418h]
v20 = -2i64;
v4 = a1;
qword_1300F478 = (__int64)off_1300A800;
v5 = 0;
v18 = 2;
v19 = 0;
LOBYTE(a4) = 1;
v6 = sub_13005B80(off_1300A800, &xmmword_1300F250, a1, a4, *(_QWORD *)&v18, *(_QWORD *)&v19);
if ( v6 < 0 )
{
LODWORD(xmmword_1300F250) = 700;
if ( !(_DWORD)xmmword_1300F290 )
LODWORD(xmmword_1300F290) = sub_130061E0(*((_QWORD **)&xmmword_1300F280 + 1));
if ( (unsigned __int8)sub_13006A20(v4, (__int64)"assembler", (__int64)&v18) && (unsigned __int8)sub_13004A90(&v18) )
{
if ( (unsigned __int8)sub_13006A20(v4, (__int64)"codestart", (__int64)&v18)
&& (LOBYTE(v14) = 1, (unsigned __int8)sub_13006200(&v18, &qword_1300F4D0, v14)) )
{
*((_QWORD *)&xmmword_1300F2A0 + 1) = qword_1300F4D0;
}
else
{
*((_QWORD *)&xmmword_1300F2A0 + 1) = 0i64;
}
if ( (unsigned __int8)sub_13006A20(v4, (__int64)"retcodes", (__int64)&v18)
&& (LOBYTE(v15) = 1, (unsigned __int8)sub_13006200(&v18, &qword_1300F4B8, v15)) )
{
*(_QWORD *)&xmmword_1300F2B0 = qword_1300F4B8;
}
else
{
*(_QWORD *)&xmmword_1300F2B0 = 0i64;
}
if ( (unsigned __int8)sub_13006A20(v4, (__int64)"instruc", (__int64)&v18)
&& (unsigned __int8)sub_130063C0((__int64)&v18, &qword_1300F488, v16) )
{
*(_QWORD *)&xmmword_1300F2C0 = qword_1300F488;
*(_QWORD *)&xmmword_1300F280 = sub_130021F0;
v5 = 1;
}
else
{
sub_13003EA0(&Dst, "Missing processor instructions definition");
}
}
}
最重要的地方是13003b51h处的call,hook_to_notification_point(3i64, sub_130041E0)。查看ida sdk include/idp.hpp可以看到对hook_to_notification_point说明和函数原型:
/// Register a callback for a class of events in IDA
idaman bool ida_export hook_to_notification_point(
hook_type_t hook_type,
hook_cb_t *cb,
void *user_data = NULL);
hook_type_t枚举体的定义:
enum hook_type_t
{
HT_IDP, ///< Hook to the processor module.
///< The callback will receive all processor_t::event_t events.
HT_UI, ///< Hook to the user interface.
///< The callback will receive all ::ui_notification_t events.
HT_DBG, ///< Hook to the debugger.
///< The callback will receive all ::dbg_notification_t events.
HT_IDB, ///< Hook to the database events.
///< These events are separated from the ::HT_IDP group
///< to speed things up (there are too many plugins and
///< modules hooking to the ::HT_IDP). Some essential events
///< are still generated in th ::HT_IDP group:
///< make_code, make_data
///< This list is not exhaustive.
///< A common trait of all events in this group: the kernel
///< does not expect any reaction to the event and does not
///< check the return code. For event names, see ::idb_event.
HT_DEV, ///< Internal debugger events.
///< Not stable and undocumented for the moment
HT_VIEW, ///< Custom/IDA views notifications.
///< Refer to ::view_notification_t
///< for notification codes
HT_OUTPUT, ///< Output window notifications.
///< Refer to ::msg_notification_t
///< (::view_notification_t)
HT_GRAPH, ///< Handling graph operations
///< (::graph_notification_t)
HT_LAST
};
第一个参数为3,即HT_IDB,从注释看出make_code, make_data等事件会触发回调。回调函数的原型如下
typedef ssize_t idaapi hook_cb_t(void *user_data, int notification_code, va_list va);
可以看出sub_130041E0的第二个参数即为notification_code,此处为processor_t::event_t。其定义可以在ida文档中找到,也可通过qword_1300E000处得知。
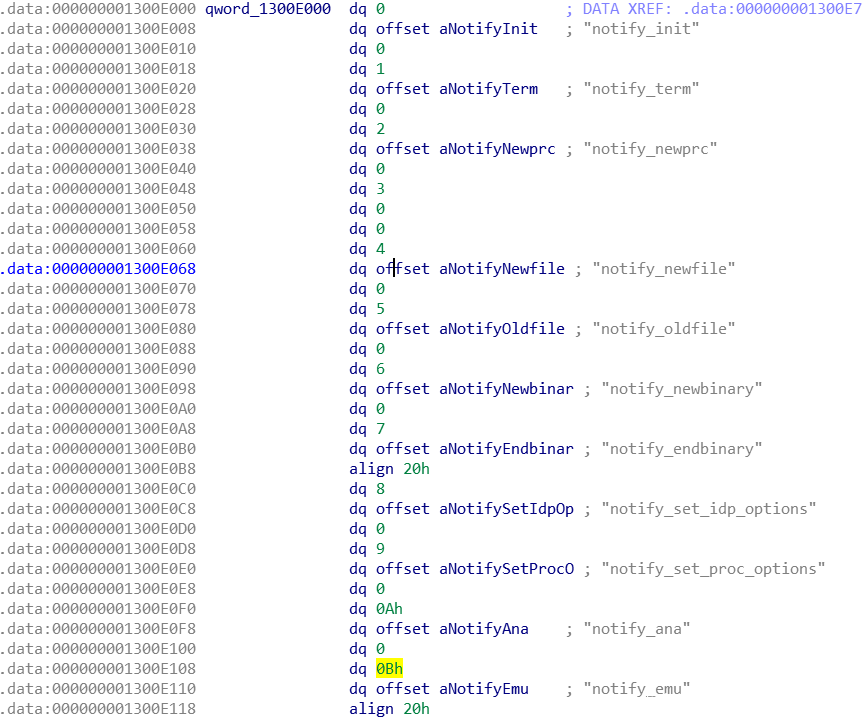
函数会根据不同的notification_code调用不同的回调函数。
编写最简单的ida处理器模块
定义处理器属性
修改sample_processor_t为chip8_processor_t。首先需要设置一些处理器模块的基本信息。每个处理器模块都需要有id,name。这里直接在模板基础上更改就好,挑一个没人用的id,psnames与plnames为名字缩写与全称。cnbits与dnbits设为8即可,assembler暂时无需更改。flag指定了一些特性,根据需要设置。PTRSZ为指针大小,由于chip8地址空间有0x1000个字节,这里设置为2即16bits。
定义寄存器
为了代码可读性,学习ebc.py做法,将定义寄存器的代码单独编写为一个方法并在chip8_processor_t的init方法中调用。设置好chip8所用的寄存器。由于ida的实现问题,虽然用不到段寄存器,但仍需要设置好假的段寄存器。
def init_registers(self):
# register names
self.reg_names = [
# General purpose registers
"V0",
"V1",
"V2",
"V3",
"V4",
"V5",
"V6",
"V7",
"V8",
"V9",
"VA",
"VB",
"VC",
"VD",
"VE",
"VF",
#
"PC",# Instruction pointer
"I", # Index register 12bit
"DT",# Delay timer
"ST",# Sound timer
# Fake segment registers
"CS",
"DS"
]
# number of registers (optional: deduced from the len(reg_names))
self.regs_num = len(self.reg_names)
# Segment register information (use virtual CS and DS registers if your
# processor doesn't have segment registers):
self.reg_first_sreg = 19 # index of CS
self.reg_last_sreg = 20 # index of DS
# size of a segment register in bytes
self.segreg_size = 0
# You should define 2 virtual segment registers for CS and DS.
# number of CS/DS registers
self.reg_code_sreg = 19
self.reg_data_sreg = 20
设置指令集
在刚才分析script.dll时可以看到ida需要一个instruc属性存放指令信息,同时我们在解析指令时可以查表更加方便。还需要设置chip8_processort的itypexx与之对应。这里同样编写一个在init中调用的方法,初始化指令表。这里指令对应的助记表示是根据github上CHIP-8项目的指令集说明。由于指令无法按顺序解析,定义itable时每条指令设置mask与opcode,通过操作数与掩码结合来判断指令,要注意用这种方法定义指令集需要将更精确的匹配项放在前面。idef的d属性为对应指令的解析方法,这里根据操作数类型等编写了几个方法解析并设置操作数信息,方便后面分析过程分析指令。不同指令的文字表达相同,所以不能像ebc.py中将指令名称直接与"itype"拼接作为属性名称,而是将指令的操作数与"itype"拼接后作为属性名称。最后还需要设置指令集表项的起始索引与结束索引self.instruc_start``self.instruc_end,ret指令的itype信息self.icode_return。
def init_instruction(self):
class idef:
def __init__(self, opcode, mask, name, cf, d, cmt = None):
self.opcode = opcode
self.mask = mask
self.name = name
self.cf = cf
self.d = d
self.cmt = cmt
self.itable = [
idef(opcode=0x00E0, mask=0xffff, name="CLS", d=self.decode_OP, cf=0, cmt="Clear video memory"),
idef(opcode=0x00EE, mask=0xffff, name="RET", d=self.decode_OP, cf=CF_STOP, cmt="Return from subroutine"),
idef(opcode=0x0000, mask=0xf000, name="SYS", d=self.decode_NNN_mem, cf=CF_USE1, cmt="Call CDP1802 subroutine at NNN"),
idef(opcode=0x1000, mask=0Xf000, name="JP", d=self.decode_NNN_mem, cf=CF_USE1|CF_JUMP, cmt="Jump to address NNN"),
idef(opcode=0x2000, mask=0xf000, name="CALL", d=self.decode_NNN_mem, cf=CF_USE1|CF_CALL, cmt="Call CHIP-8 subroutine at NNN"),
idef(opcode=0x3000, mask=0xf000, name="SE", d=self.decode_XNN, cf=CF_USE1|CF_USE2|CF_JUMP, cmt="Skip next instruction if VX == NN"),
idef(opcode=0x4000, mask=0xf000, name="SNE", d=self.decode_XNN, cf=CF_USE1|CF_USE2|CF_JUMP, cmt="Skip next instruction if VX != NN"),
idef(opcode=0x5000, mask=0xf00f, name="SE", d=self.decode_XY, cf=CF_USE1|CF_USE2|CF_JUMP, cmt="Skip next instruction if VX == VY"),
idef(opcode=0x6000, mask=0xf000, name="LD", d=self.decode_XNN, cf=CF_USE1|CF_CHG1|CF_USE2, cmt="VX = NN"),
idef(opcode=0x7000, mask=0xf000, name="ADD", d=self.decode_XNN, cf=CF_USE1|CF_CHG1|CF_USE2, cmt="VX = VX + NN"),
idef(opcode=0x8000, mask=0xf00f, name="LD", d=self.decode_XY, cf=CF_USE1|CF_CHG1|CF_USE2, cmt="VX = VY"),
idef(opcode=0x8001, mask=0xf00f, name="OR", d=self.decode_XY, cf=CF_USE1|CF_CHG1|CF_USE2, cmt="VX = VX OR VY"),
idef(opcode=0x8002, mask=0xf00f, name="AND", d=self.decode_XY, cf=CF_USE1|CF_CHG1|CF_USE2, cmt="VX = VX AND VY"),
idef(opcode=0x8003, mask=0xf00f, name="XOR", d=self.decode_XY, cf=CF_USE1|CF_CHG1|CF_USE2, cmt="VX = VX XOR VY"),
idef(opcode=0x8004, mask=0xf00f, name="ADD", d=self.decode_XY, cf=CF_USE1|CF_CHG1|CF_USE2, cmt="VX = VX + VY; VF = 1 if overflow else 0"),
idef(opcode=0x8005, mask=0xf00f, name="SUB", d=self.decode_XY, cf=CF_USE1|CF_CHG1|CF_USE2, cmt="VX = VX - VY; VF = 1 if not borrow else 0"),
idef(opcode=0x8006, mask=0xf00f, name="SHR", d=self.decode_XY, cf=CF_USE1|CF_CHG1|CF_USE2, cmt="VF = LSB(VX); VX = VX » 1 (** see note)"),
idef(opcode=0x8007, mask=0xf00f, name="SUBN", d=self.decode_XY, cf=CF_USE1|CF_CHG1|CF_USE2, cmt="VX = VY - VX; VF = 1 if not borrow else 0"),
idef(opcode=0x800E, mask=0xf00f, name="SHL", d=self.decode_XY, cf=CF_USE1|CF_CHG1|CF_USE2, cmt="VF = MSB(VX); VX = VX « 1 (** see note)"),
idef(opcode=0x9000, mask=0xf00f, name="SNE", d=self.decode_XY, cf=CF_USE1|CF_USE2|CF_JUMP, cmt="Skip next instruction if VX != VY"),
idef(opcode=0xA000, mask=0xf000, name="LD", d=self.decode_LD_I, cf=CF_USE1, cmt="I = NNN"),
idef(opcode=0xB000, mask=0xf000, name="JP", d=self.decode_JP_V0, cf=CF_USE1|CF_JUMP, cmt="Jump to address NNN + V0"),
idef(opcode=0xC000, mask=0xf000, name="RND", d=self.decode_XY, cf=CF_USE1|CF_CHG1|CF_USE2, cmt="VX = RND() AND NN"),
idef(opcode=0xD000, mask=0xf000, name="DRW", d=self.decode_XYN, cf=CF_USE1|CF_USE2|CF_USE3, cmt="Draw 8xN sprite at I to VX, VY; VF = 1 if collision else 0"),
idef(opcode=0xE09E, mask=0xf0ff, name="SKP", d=self.decode_X, cf=CF_USE1|CF_JUMP, cmt="Skip next instruction if key(VX) is pressed"),
idef(opcode=0xE0A1, mask=0xf0ff, name="SKNP", d=self.decode_X, cf=CF_USE1|CF_JUMP, cmt="Skip next instruction if key(VX) is not pressed"),
idef(opcode=0xF007, mask=0xf0ff, name="LD", d=self.decode_LD_VX_DT, cf=CF_USE1|CF_CHG1, cmt="LD VX, DT;Sets VX to the value of the delay timer."),
idef(opcode=0xF00A, mask=0xf0ff, name="LD", d=self.decode_LD_K, cf=CF_USE1|CF_CHG1, cmt="Wait for key press, store key pressed in VX"),
idef(opcode=0xF015, mask=0xf0ff, name="LD", d=self.decode_LD_DT_VX, cf=CF_USE1, cmt="DT = VX;Sets the delay timer to VX."),
idef(opcode=0xF018, mask=0xf0ff, name="LD", d=self.decode_LD_ST, cf=CF_USE1, cmt="ST = VX;Sets the sound timer to VX."),
idef(opcode=0xF01E, mask=0xf0ff, name="ADD", d=self.decode_ADD_I, cf=CF_USE1, cmt="I = I + VX; VF = 1 if I > 0xFFF else 0"),
idef(opcode=0xF029, mask=0xf0ff, name="LD", d=None, cf=CF_USE1, cmt="I = address of 4x5 font character in VX (0..F) (* see note)"),
idef(opcode=0xF033, mask=0xf0ff, name="BCD", d=self.decode_X, cf=CF_USE1, cmt="set_BCD(Vx);*(I+0)=BCD(3);*(I+1)=BCD(2);*(I+2)=BCD(1);Store BCD representation of VX at I (100), I+1 (10), and I+2 (1); I remains unchanged"),
idef(opcode=0xF055, mask=0xf0ff, name="LD", d=self.decode_STORE_I, cf=CF_USE1, cmt="Store V0..VX (inclusive) to memory starting at I; I remains unchanged"),
idef(opcode=0xF065, mask=0xf0ff, name="LD", d=self.decode_LOAD_I, cf=CF_USE1, cmt="Load V0..VX (inclusive) from memory starting at I; I remains unchanged")
]
Instructions = []
i = 0
for x in self.itable:
d = dict(name=x.name, feature=x.cf)
if x.cmt != None:
d['cmt'] = x.cmt
Instructions.append(d)
setattr(self, 'itype_' + ("%04X" % x.opcode), i)
i += 1
# icode of the first instruction
self.instruc_start = 0
# icode of the last instruction + 1
self.instruc_end = len(Instructions) + 1
# Array of instructions
self.instruc = Instructions
# Icode of return instruction. It is ok to give any of possible return
# instructions
self.icode_return = self.itype_00EE
实现回调函数
实现分析与输出
首先要实现notify_ana(self, insn),这里因为实现了单独的解析函数并设置好了指令表,直接获取两字节数据与掩码and后查表即可,如果遇到不认识的操作数,return 0告诉ida识别出现了问题。识别正常则返回解析指令及操作数的大小。
def get_idef(self, opcode):
for i in self.itable:
if opcode & i.mask == i.opcode:
return i
return None
def notify_ana(self, insn):
"""
Decodes an instruction into insn
Returns: insn.size (=the size of the decoded instruction) or zero
"""
opcode = insn.get_next_word()
ins = self.get_idef(opcode)
if ins == None:
return 0
else:
ins.d(insn, opcode)
insn.itype = getattr(self,"itype_" + ("%04X" % ins.opcode) )
# Return decoded instruction size or zero
return insn.size
decode系列用于解析操作数的函数大同小异。
def decode_XY(self, insn, opcode):
insn.Op1.type = o_reg
insn.Op1.reg = (opcode & 0x0f00)>>8
insn.Op2.type = o_reg
insn.Op2.reg = (opcode & 0x00f0)>>4
def decode_NNN_mem(self, insn, opcode):
insn.Op1.type = o_near
insn.Op1.dtype = dt_word
insn.Op1.addr = opcode & 0xfff
......
然后实现notify_out_operand(self, ctx, op)与notify_out_insn(self, ctx)两个方法,一个负责输出操作数,一个负责输出指令。
def notify_out_insn(self, ctx):
"""
Generate text representation of an instruction in 'ctx.insn' structure.
This function shouldn't change the database, flags or anything else.
All these actions should be performed only by u_emu() function.
Returns: nothing
"""
ctx.out_mnemonic()
ctx.out_one_operand(0)
for i in range(1, 4):
op = ctx.insn[i]
if op.type == o_void:
break
ctx.out_symbol(',')
ctx.out_char(' ')
ctx.out_one_operand(i)
ctx.set_gen_cmt()
ctx.flush_outbuf()
在notify_out_insn中调用ctx.out_mnemonic来输出instruc中指令的name。之后调用ctx.out_one_operand(i)输出操作数,此方法会调用到下面的notify_out_operand(self, ctx, op)回调来输出操作数信息。其中op参数会携带指令操作数信息,在分析时可以设置specval属性来携带额外信息给输出方法。
def notify_out_operand(self, ctx, op):
"""
Generate text representation of an instructon operand.
This function shouldn't change the database, flags or anything else.
All these actions should be performed only by u_emu() function.
The output text is placed in the output buffer initialized with init_output_buffer()
This function uses out_...() functions from ua.hpp to generate the operand text
Returns: 1-ok, 0-operand is hidden.
"""
optype = op.type
fl = op.specval
if optype == o_reg:
ctx.out_register(self.reg_names[op.reg])
elif optype == o_imm:
# for immediate loads, use the transfer width (type of first operand)
# if op.n == 1:
# width = self.dt_to_width(ctx.insn.Op1.dtype)
# else:
# width = OOFW_32 if self.PTRSZ == 4 else OOFW_64
ctx.out_value(op,8)
elif optype in [o_near, o_mem]:
r = ctx.out_name_expr(op, op.addr, BADADDR)
if not r:
ctx.out_tagon(COLOR_ERROR)
ctx.out_btoa(op.addr, 4)
ctx.out_tagoff(COLOR_ERROR)
remember_problem(PR_NONAME, ctx.insn.ea)
elif optype == o_displ:
if fl & self.FL_K == self.FL_K:
ctx.out_symbol('[')
ctx.out_char('K')
ctx.out_symbol(']')
else:
ctx.out_symbol('[')
ctx.out_register(self.reg_names[op.reg])
ctx.out_symbol(']')
else:
return False
return True
到这里已经可以使用这个处理器模块了,将其放置在ida目录的procs下。加载文件时选择处理器类型CHIP-8。在想要反汇编的地方c来make_code,成功。但是会发现按一下c只识别一个,指令之间没有联系,更别提跳转了。如下图

这就是因为没有实现notify_emu方法,指令解析完后没有互相的引用导致的。下面来实现模拟部分。
实现模拟
def notify_emu(self, insn):
"""
Emulate instruction, create cross-references, plan to analyze
subsequent instructions, modify flags etc. Upon entrance to this function
all information about the instruction is in 'insn' structure.
If zero is returned, the kernel will delete the instruction.
"""
feature = insn.get_canon_feature()
flow = (feature & CF_STOP) == 0
if feature & CF_JUMP:
remember_problem(PR_JUMP, insn.ea)
if insn.itype == self.itype_1000:
add_cref(insn.ea, insn.Op1.addr, fl_JN)
flow = False
elif insn.itype == self.itype_2000:
add_cref(insn.ea, insn.Op1.addr, fl_CN)
elif insn.itype in (self.itype_3000, self.itype_4000, self.itype_5000, self.itype_9000):
add_cref(insn.ea, insn.ea + insn.size*2, fl_JN)
if flow:
add_cref(insn.ea, insn.ea + insn.size, fl_F)
return 1
JP与CALL指令根据操作数来设置引用地址。所有JP、CALL以及RET指令在定义itable的时候feature都设置了CF_STOP标志位,其不引用相邻指令,除此之外指令对相邻指令添加引用。简单实现emu之后再用ida载入,设置加载地址为0x200(见CHIP8简介)。直接按p定义函数,效果如下图(载入的rom文件:BLITZ)

尾声
实现了一个非常简单的指令集的处理器模块,关于trace_sp,switch等均未涉及到,算是对idp有一个简单的了解和实践,完整代码:chip8.py。珠玉在前,下面给出一些过程中参考的优秀的文章,感谢大佬们的指点。