
一、背景
随着互联网的高速发展与普及,网络已经成为日常生产生活的基础设施。在数字化转型的大环境下,人们的衣食住行均与互联网产生交集,每个交集的背后都有数据在流动,但同时数据泄露、个人隐私泄露、数据违规使用也层出不穷,如何更好的保障数据安全性,已成为网络空间安全的新课题。
字节跳动长久以来持续重视数据安全,以最小化原则为宗旨,采用分类分级管控的基本手段,基于公司统一的安全制度和策略,面向全媒介不断强化多粒度数据的安全防控能力,旨在不断探索安全与效率平衡的最优解。
字节跳动数据平台是公司大数据体系的核心,承载了大数据的全生命周期操作。为了防范大数据场景下的数据安全风险,数据平台除了常规的分类分级、加密脱敏、数据销毁能力,还创新的在访问控制方面落地了“智能审批”能力,强化权限审批中的深层风险洞察能力。
二、目标设定
数据平台的访问控制体系(如图1),构筑于IBAC(基于身份的访问控制)、RBAC(基于角色的访问控制)和OBAC(基于组织的访问控制)相融合的复合访问控制模型,为了保障高效的审批,数据平台于2021年上线了自动审批能力,节省审批时长近40%,截止至2022年6月底累计411万+小时。
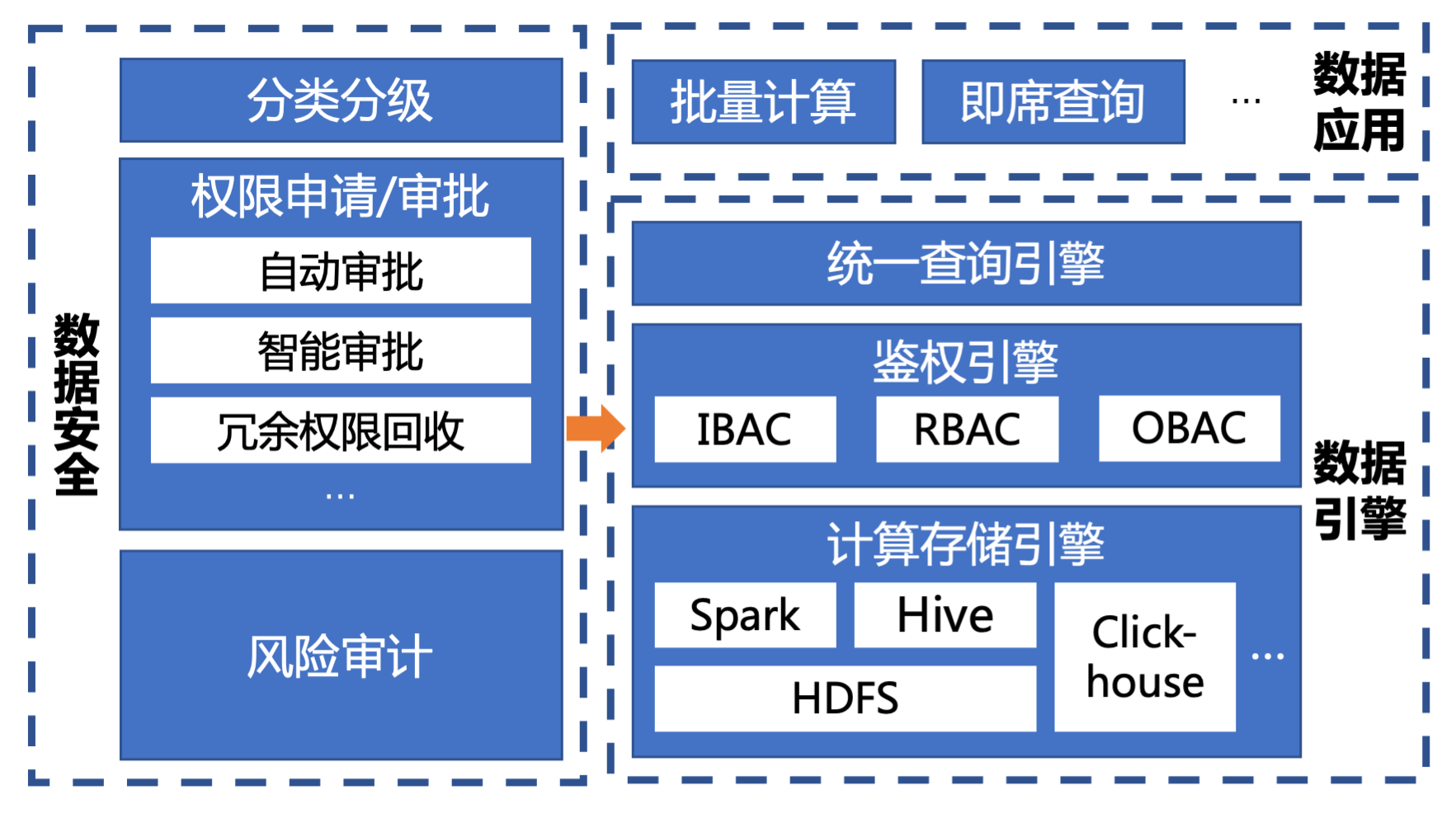
图1. 字节跳动数据平台访问控制体系概览
基于属性设置的自动审批策略(ABAC思想)确保了多样化、细粒度的管控能力,由审批人配置低风险场景判定规则,转换人工审批为自动审批+事后审计的工作流,有效提升了数据使用效率,但无法做到人工审批的风险决断准确性,难以洞察到深层风险。为了进一步打通上下游风险信息,深化审批人场景全局风险感知,数据平台需要在自动审批的基础上额外构筑全方位、高精度、易理解的风险洞察和透传能力。
三、体系与实践
字节跳动数据平台于2021年下半年开始对接公司内部风险感知能力,协同搭建了智能审批模型,基于HBAC(基于历史的访问控制)的思想,利用历史数据训练模型、实时数据作为请求输入,逐步构筑了如图2的智能审批功能体系。

图2. 智能审批功能体系(绿色为“低风险” 工单流转,红色为“高风险”工单流转)
数据平台的智能审批功能是在原有“权限申请-正常审批流程-结果处置及返回”流程的基础上,对第二环节进行改造,提交工单数据给智能审批模型,并基于返回结果中的风险评分和标签分级处置——“低风险”的工单智能审批通过,无需人工操作;“中风险”的工单依据自动审批策略正常执行自动审批或人工审批;“高风险”的工单忽略自动审批配置、透出风险标签,并实施人工审批。
上述智能审批模型采用离线数据自动化迭代的方式,解耦平台后端和模型以实现轻量化模型升级成本,应用时间衰减函数根据风险比例动态调整风险标签阈值,并建立相应风险分布监控和报警机制,确保符合最新安全态势。每次访问均基于传入工单,实时获取其他风控相关数据源,秒级响应,计算并返回风险评分与标签。
当前的智能审批模型基于聚类算法、相似度算法等基础能力构建,最终形成了多层次的风险度量模型,主要包含人员风险模型、资源风险模型和人员-资源关联模型三个方面。其中人员风险模型基于获权人的人力资源状态、获权人数据平台和其他办公应用行为风险、当前权限留存和使用情况等方面进行训练;资源风险模型基于资源的密级、数据生产层级、使用热度、当前权限留存和使用情况等方面进行训练;人员资源管理模型方面,则是先基于当前权限得出人员聚类和资源聚类,以表示“人员×人员”关联度和“资源×资源”关联度,再通过计算同群组内其他人员和对应资源群组的重合度,得出“人员×资源关联度”,也即同类人员已有该(类)资源权限超过一定阈值(例如:90%以上),则关联度高,否则关联度低,权限必要性和合理性可能较低。
四、成效与展望
字节跳动数据平台的智能审批能力上线以来,有效地帮助更多审批人进行数据安全风险判断,截止至2022年6月底,实现了高风险场景4.92个百分点的识别率提升,并累计节约低风险工单审批时长4.25万小时。
目前,数据平台中的数据应用、数据开发套件、数据引擎均已上线火山引擎大数据系列产品矩阵中,努力为用户构建安全可靠、高效易用的数据全生命周期。
将来,数据平台还会在智能审批的模型中引入更多风险因子并持续优化、迭代,继续强化对用户数据、公司数据的安全保障,以知情同意和合理必要为底线,不断压缩数据泄露风险,并减少合规数据使用的审批耗时。
作为字节跳动数据平台背后的安全治理与合规团队,我们将持续建立健全公司信息安全管理体系,严格满足隐私合规要求,做用户个人数据的守护者,让每个用户都可以安心的体验数字化转型下的新时代。