
联邦学习从本质上很容易受到投毒攻击,因为不会将训练样本发布给可信机构并进行检查。在集中式学习范式中,对投毒攻击进行了广泛的研究,但是,分布式投毒攻击(其中不止一个攻击者相互勾结,并将恶意训练样本注入其自己的本地模型中)可能会导致直观上联邦学习的更大灾难。
在本文中,通过实际实施联邦学习系统和分布式投毒攻击,获得了有关投毒训练样本数量,攻击者与攻击成功率之间关系的一些观察结果。此外提出了一种方案Sniper,以消除训练过程中恶意参与者的投毒本地模型。Sniper通过解决最大团问题来识别良性本地模型,并且在全局模型更新过程中将忽略可疑(投毒)的本地模型。实验结果证明了Sniper的功效。即使有三分之一的参与者是攻击者,攻击成功率也会降低到2%左右。
0x01 Introduction
与集中式学习相比,联邦学习具有分布式存储,计算和私有数据保留的优势。在联邦学习中,参与者(训练终端)报告其本地训练的模型而不是私人训练数据,这保护了参与者的隐私,但使汇总和更新全局模型的过程更容易受到投毒攻击。在集中式和独立式环境中,投毒攻击已经得到了很好的研究,最常用的投毒策略是标签翻转(label-flflipping),其中攻击者将训练样本的标签修改为另一类,但是数据的特征保持不变,这会导致攻击的分类器分类错误。
几位研究人员证明了在分布式学习场景中单人投毒攻击的效率。 Bhagoji等[1]探索由单个非共谋恶意参与者发起的联邦学习模式投毒攻击的威胁。Hayes等[2]评估多方机器学习中的污染攻击。当训练集中包含5%的污染数据时,污染攻击成功率达到38%。Fung等考虑联邦学习对基于女巫的投毒攻击的脆弱性[3]。但是,很少有研究调查针对联邦学习的分布式投毒攻击,其中多个恶意参与者将有毒的训练样本注入到训练过程中,并且具有相同的攻击目标。目前尚不清楚多个攻击者的分布式投毒是否比单个攻击者的传统投毒更有效(在总数相同的投毒训练样本下),攻击者和投毒样本的数量如何影响攻击成功率?
在本文中建立了一个联邦学习系统,并实现了FederatedAveraging算法。针对不同数量的攻击者和投毒的训练样本发起了翻转标签的投毒攻击,并检查了相应的攻击成功率。根据实验结果获得了关于攻击者数量,投毒样本与攻击成功率之间关系的三个观察结果。首先,攻击成功率与投毒样本数量成线性关系。其次,增加攻击者的数量可以提高攻击成功率,而不会改变投毒样本的总数。第三,随着更多攻击者的参与,攻击成功率随着投毒样本数量的增加而更快。衡量模型之间的距离,并观察到为了使全局模型朝错误的方向更新,攻击者必须报告与诚实模型有较大距离的投毒本地模型。因此提出了一种名为Sniper的方案,供服务器识别一组诚实的本地模型,以便可以使用它来聚合干净的全局模型。在Sniper中,服务器构建一个图形,其中顶点引用在更新期间从参与者收集的本地模型,并且如果两个本地模型足够接近(即,具有相对较小的欧几里得距离),则它们之间将存在一条边。然后,服务器通过解决图中的最大团问题来识别诚实的本地模型。全局模型是通过仅汇总结果派系所包含的那些本地模型而获得的。实验结果表明,即使在Sniper的保护下,即使有三分之一的参与者是攻击者,攻击成功率也下降到2%。
0x02 Federated Learning and Distributed Poisoning
A.联邦学习
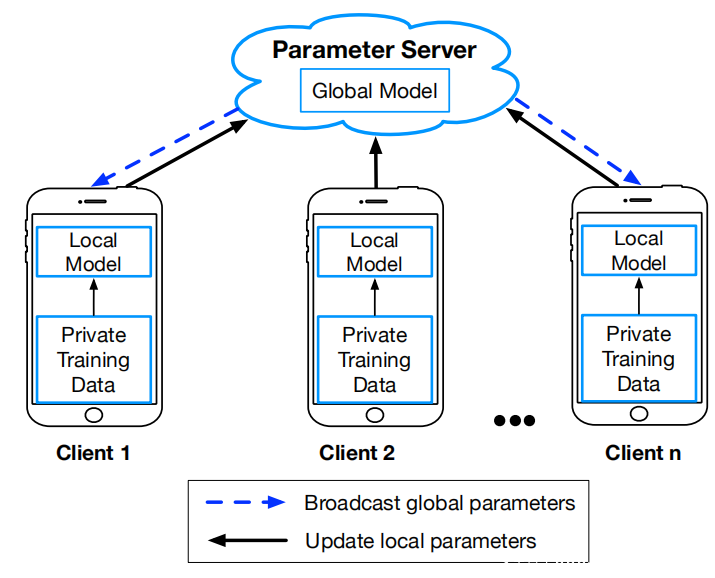
考虑一个由N个参与者$O^k$(k≤N)组成的联邦学习设置,每个参与者都可以访问本地私人训练数据集Dk和中央参数服务器S(如上图所示)。在每个时期t,每个参与者$O^k$训练具有本地参数向量$M^t_G$∈$R^n$ 的新本地模型,其中n是参数空间的维数,并将模型(即对应的参数向量)发送给S。 S从所有参与者接收$M^t_k$(k = 1,…,N),它执行FederatedAveraging算法以获取具有全局参数矢量$M^t_G$∈$R^n$的新全局模型。
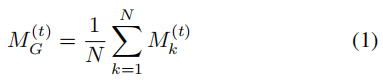
从S接收到$M^t_G$后,每个参与者执行以下随机梯度下降算法以生成新的本地模型。
其中η,L和▽L分别代表学习率,损失函数和梯度。
B.投毒攻击
深度学习需要大量包含个人隐私信息的数据,例如家庭住址,工作地点,宗教信仰和健康状况。释放数据不仅对用户有害,而且故意污染数据也可能导致严重事故。例如,交通信号标志识别系统的训练数据集被有意修改,并且自动驾驶汽车使用该系统来区分交通标志。尽管失真很小,例如更改样品标签,但可能会导致交通事故。本杰明等[6]将这种操纵定义为投毒攻击。他们将投毒攻击应用于异常检测,攻击者的目标是导致拒绝服务。之后在SVM和深度学习中应用投毒攻击。
投毒攻击场景可以分为两类:
模型失败投毒攻击(Model failure poisoning attack):攻击者的目标是使模型不可用。换句话说,攻击者的目标是任意的,他们的一致目标是使分类器给出错误的预测。
目标错误投毒攻击(Target error poisoning attack):这种投毒攻击还会使模型的预测错误,但目标错误投毒攻击会迫使模型将特定类(源标签)错误分类为另一个目标类(目标标签)。
产生投毒样本的主要方法有两种(也称为对抗性样本):标签翻转和后门。翻转标签要求攻击者更改训练数据的标签,并保持数据特征不变。在后门攻击中,攻击者首先将原始训练数据的一小部分修改为秘密模式(白色正方形或水印),然后将其重新标记为目标标签。实际上,该模式是触发样本的触发条件,并将其分类为目标类别。
还有其他污染数据的方法,例如向熊猫图像添加噪声,使模型将其预测为长臂猿,但它们作用于模型测试短语,这与本文攻击目标不同。此外,标签翻转攻击不需要任何技术知识和预训练。攻击者更容易启动。
C.分布式投毒

如算法1所示,联邦学习系统中的分布式投毒攻击是指,不止一个攻击者使用与方程式4和方程式5中诚实的参与者相同的损失函数和超参数来训练自己的本地模型,但进行了投毒训练数据集(见下图)。在这项工作中,采用以下假设:
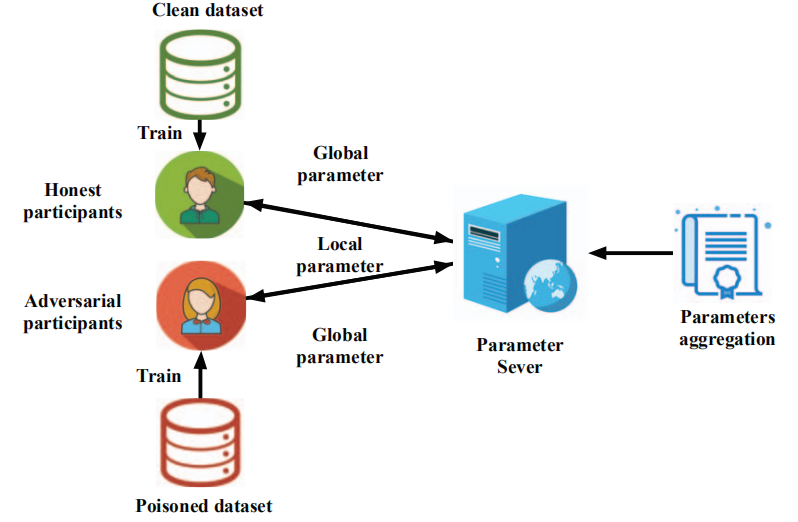
•所有攻击者合谋并具有相同的攻击目标。特别是,他们发起了目标错误投毒攻击。
•攻击者无法观察其他诚实参与者的训练数据。这意味着攻击者无法推断任何诚实参与者的参数。
•攻击者的数量不得超过N / 3。
在P(P≤N / 3)攻击者隐藏在N个参与者中的分布式投毒攻击下,可以将S上的全局模型聚合算法重写为等式3:
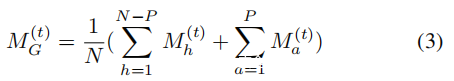
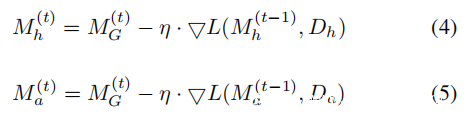
定义攻击的成功率如下:
定义1.(攻击成功率)如果投毒模型输出源标签I的期望目标标签T,则攻击成功,否则攻击失败。对于模型M,攻击的成功率SR给出为:
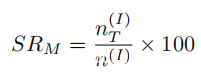
0x03 Strategies of Disteibuted Poisoning
A.实验设置
评估了手写数字图像数据集MNIST [4]上的分布式投毒攻击的效率。它的训练数据集包含50,000个标记为0-9的样本,其测试数据集包含10,000个样本。其中的图像尺寸为28×28。根据Shen[6]等人的研究,在区分手写数字0到9的分类器上发动有针对性的投毒攻击,最简单和最困难的源标签和目标标签对分别是(6,2)和(8,4)。因此在实验中设定了以下两个攻击目标:
•目标1:给定数字图像6,模型输出2。
•目标2:给定数字图像为8,模型输出为4。
为了消除其他标签的影响,仅使用带有目标和源标签的样本来训练二进制分类器(大约10,000个样本)。利用标签翻转生成投毒样本,即更改训练样本的标签并保持样本特征不变,因为它不需要任何有关分类器和预训练的知识。
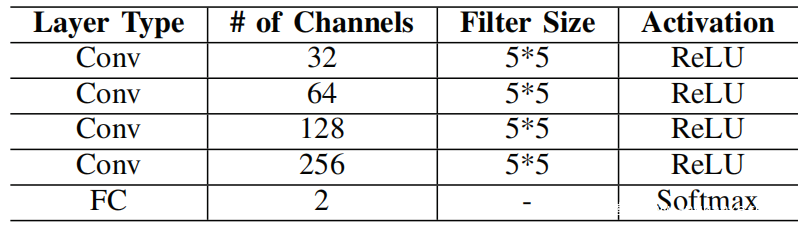
对于以上数据集,实现了一个由十名参与者组成的联邦学习系统。培训数据平均分配给每个参与者。参与者同意相同的模型架构和超参数。选择一个卷积神经网络(CNN)(请参阅下表中的体系结构),它具有四个卷积层和一个完整的连接层,并使用Relu作为前四层的激活函数,并使用Softmax作为输出的激活函数层。将批量大小B设置为十。学习率η以0.098的指数速率从0.08衰减。此外添加了正则化项(λ= 0.01)以防止模型过度拟合。将模型中每个神经元的权重初始化为从正态分布N(0,0.022)采样的随机值,并将偏差初始化为0。
B.基准联邦学习系统
在基准系统中,所有参与者都是诚实的,仅使用干净的训练样本来一起训练全局模型。在实验中,每个参与者随机选择250个训练样本,分别带有目标和来源标签。从测试数据集中随机选择500个带有来源标签的测试样本。为了评估基准全局模型的性能,运行了20次实验,并获得了平均值。根据实验结果,全局模型的准确性几乎为100%。但是,如果参与者在不与他人共享参数的情况下训练本地模型,则本地模型的准确性约为90%。这表明本地模型的聚集确实导致了更好的全局模型。
C.分布式投毒攻击的影响因素

认为以下两个关键因素会影响分布式投毒攻击的攻击成功率,即投毒样本的数量(所有攻击者)和攻击者的数量。因此,将攻击者的数量P从1更改为3,并在一定数量的攻击者下,以50的间隔将投毒样本的总数从300增加到500,然后将投毒样本平均分配给所有攻击者。最大攻击者数量应少于参与者总数的1/3,否则联邦平均算法将不覆盖。如上图所示,当攻击者数大于3时,平均算法的损失不再减少。

分别检查了不同数量的投毒样本和攻击者对目标1和2的攻击成功率,如下图(a)和(b)所示。此外将投毒样本的数量和平均攻击成功率分别视为自变量(x)和因变量(y)。考虑到特定数量的攻击者,根据不同数量的投毒样本下的平均攻击成功率进行线性回归估计。估算的线性回归模型(LRM)y = kx + c示于上表,其中k和c分别表示斜率和截距。
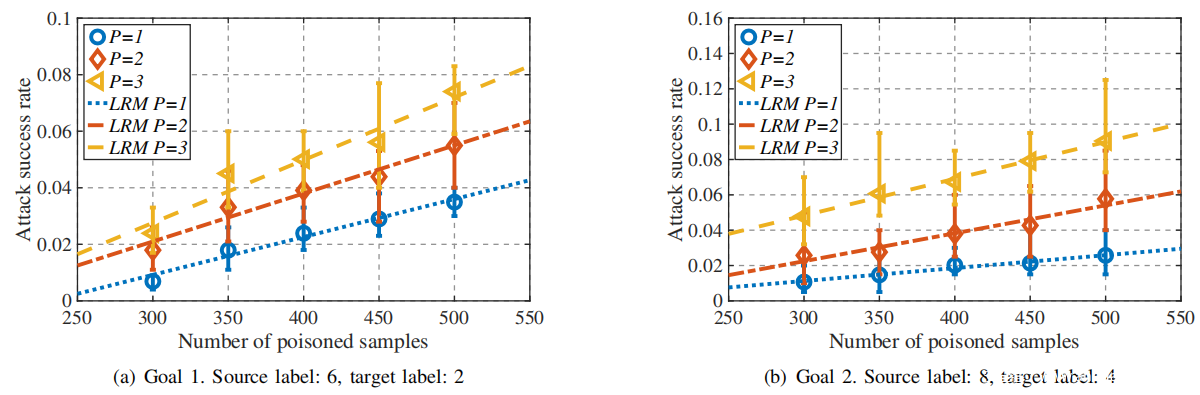
根据以上实验和分析提出以下命题:
命题1.攻击成功率随投毒样本数量线性增加。
命题2.增加攻击者数量可以提高攻击成功率,而无需更改投毒样本的数量。
命题3.LRM的斜率(即,提高攻击成功率的速度)随攻击者数量的增加而增加。
0x04 Analyzing Distributed Poisoning
给定两个模型M1和M2,利用欧几里得距离(这是测量高维空间中距离的最常用方法之一)来衡量它们之间的差异(等式6)。
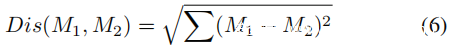
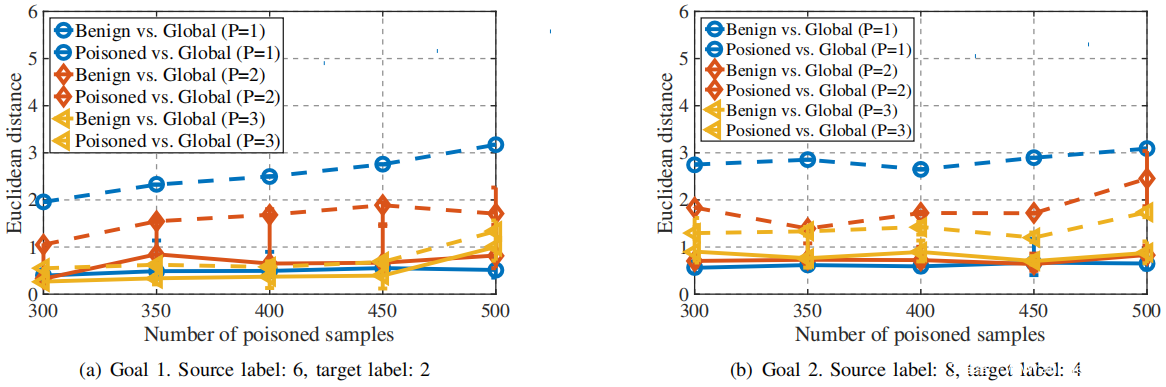
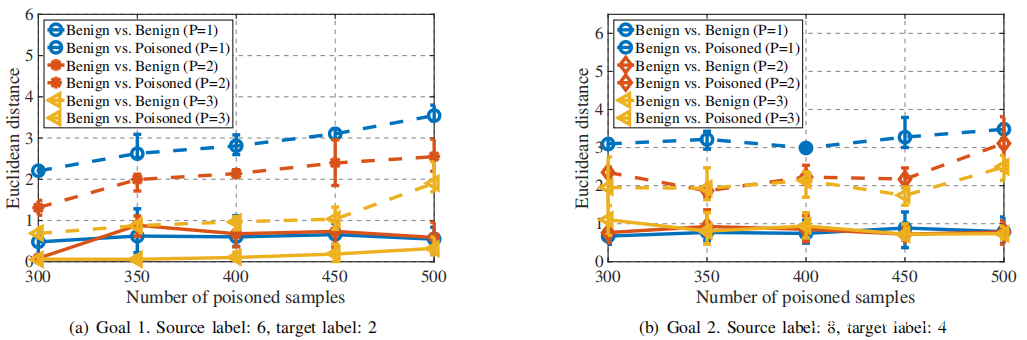
然后,对于每个攻击目标,分别计算在不同数量的投毒样本和攻击者的情况下,良性本地模型和MG之间以及投毒本地部模型和MG之间的平均,最大和最小欧几里得距离。 根据下图(a)和(b)所示的实验结果进行以下分析:
1)投毒样本数量的影响:当增加投毒样本数量时,从新的聚合全局模型M更新为投毒本地模型M’的偏差,即,下图中的α通常将减小。从上图可以看出,对于两个攻击目标,增加投毒样本数量,$M^t_G$与投毒本地模型M‘之间的模型距离将增加,即α将增大,而MG和良性本地模型之间的距离保持稳定。考虑到全局模型更新向量agg(黑色点线向量)是honest和adv的加权和向量,如式7所示,因此它偏离正确的方向θ,即
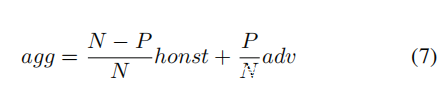
投毒样本更多意味着投毒的全局模型与良性模型有很大的偏差。 结果,聚合向量agg远离向量诚实,这意味着较高的攻击成功率。
2)攻击者数量的影响:对于一定数量的投毒样本,当攻击者数量P增加时,每个攻击者获取的投毒样本就会减少,因此从投毒模型到MG的模型距离会减小。 但是,投毒攻击的效率提高了(攻击成功率提高),这是因为全局模型聚合中涉及了更多的投毒本地模型。 此外,将投毒样本分发给更多攻击者也意味着服务器更难识别每个投毒本地模型。
0x05 Defending Against Distributed Poisoning Attack
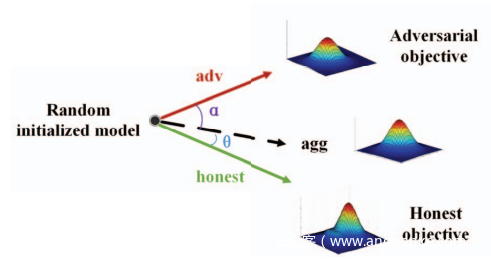
注意到,为了迫使聚集的全局模型偏离良性模型,投毒的本地模型必须不同于由诚实参与者训练的良性本地模型。如上图所示,绿色和红色矢量,即诚实和高级,表示诚实参与者和攻击者的本地模型的良性和有毒更新方向。两个向量之间的角度反映了两个优化目标之间的差异。考虑到攻击者的学习目标与诚实参与者完全不同,推测良性和投毒本地模型之间存在很大差异。因此分别计算了良性本地模型之间的欧几里得距离(来自不同的诚实参与者),以及投毒模型和良性模型之间的欧几里得距离。下图展示了不同数量的攻击者和投毒样本下的平均,最大和最小欧几里得距离。可以看出,良性和投毒本地模型之间的欧几里得距离明显大于良性本地模型之间的欧几里得距离。
基于以上分析和观察提出了一种过滤机制Sniper,该机制由参数服务器S进行处理,以通过检查本地模型之间的欧式距离来从全局模型聚合中移除攻击者。现在,更详细地解释该机制:
•首先,在从N个参与者收集本地模型Mi之后,S计算每对本地模型之间的欧几里得距离,即Dis(Mi,Mj)。
•其次,S为γ赋一个初始值(根据实验结果,将γ设置为0.5,如上图所示)。然后,它构造一个图,使得每个本地模型Mi都指向图中的顶点vi,并且如果Mi与Mj之间的欧几里得距离小于预定阈值γ,则它们之间存在边e(i,j)。
•第三,S在图中找到最大团,并检查团中的顶点数是否大于N / 2。如果是这样,则S使用等式在团中聚合顶点(本地模型),并获得全局模型。否则,用增加γ,然后转到第二步。
最大团问题是经典NP完全问题之一,使用BronKerbosch查找所有团,最大的就是最大团(诚实的用户候选集),如算法2所示。

S在每次更新期间都运行Sniper,而不仅仅是在训练开始时运行。这可以防止攻击者在几个时期或几次良性共享后上传受污染的参数。
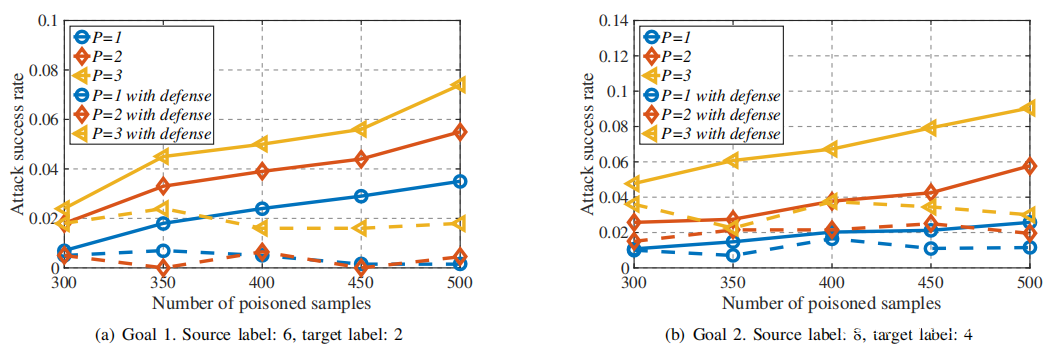
在联邦学习系统中评估Sniper的性能。ε设定为0.05。下图(a)和(b)的实验结果表明,攻击成功率显着下降。在目标1中,攻击成功率接近0。即使系统中有三个攻击者(其中Sniper过滤了更多投毒样本),攻击目标1和2的攻击成功率也分别约为2%和3%。因此,Sniper可以区分诚实的用户和攻击者,并忽略攻击者共享的模型。
0x06 Related Work
分布式深度学习已应用于实际场景。Liu等提出了一种称为联邦自主深度学习(FADL)的新方法[5],该方法使用所有数据源以分布式方式训练模型的一部分,并使用来自特定数据源的数据训练其他部分。此方法可用于使训练后的模型适应特定任务,并部分保护数据隐私。
协作学习和联邦学习中的攻击者可能很强大。他们可以推断其他用户训练集的成员资格,但是这种攻击将系统中的攻击者数量限制为1。由于攻击者仅获取全局参数,因此他无法从汇总中识别出特定用户的参数。结果,如果存在多重攻击者,则此攻击将无法成功。 Bhagoji等[1]探讨了由单一的非竞争性恶意代理发起的联邦学习中模型投毒攻击的威胁,其对抗目标是使模型以高置信度对一组选择的输入进行错误分类。
分布式学习是脆弱的,如本文实验所示,攻击者只需要修改自己的本地训练数据集的标签即可降低整体模型的性能。因此,提出了许多针对联邦学习中攻击的防御方法。Auror[6]可以检测到恶意用户,并根据被掩盖特征的异常分布生成准确的模型。
0x07 Conclusion
在本文中分析了投毒样本数量和攻击者数量如何影响变量投毒攻击的性能。攻击成功率随投毒样本数量线性增加;在投毒样本数量不变的情况下,攻击成功率随攻击者数量的增加而增加,而涉及更多的攻击者时,增加的速度会更快。
通过观察模型之间的距离,发现诚实用户和攻击者的模型处于不同的团。基于此提出了一种过滤防御机制Sniper。在每次通信期间,参数服务器都会运行它以过滤攻击者更新的参数。结果,即使在联邦学习系统中有多个攻击者,Sniper仍可以识别诚实用户并显着降低攻击成功率。
将来会在联邦学习中评估更多的聚合算法,并分析多任务投毒攻击如何攻击全局模型。此外将通过增加客户数量来扩大联邦学习的规模。
Reference
[1] A. N. Bhagoji, S. Chakraborty, P. Mittal, and S. Calo, “Analyzing federated learning through an adversarial lens,” in International Conference on Machine Learning, 2019, pp. 634–643.
[2] J. Hayes and O. Ohrimenko, “Contamination attacks and mitigation in multiparty machine learning,” in Advances in Neural Information Processing Systems, 2018, pp. 6604–6615.
[3] C. Fung, C. J. Yoon, and I. Beschastnikh, “Mitigating sybils in federated learning poisoning,” arXiv preprint arXiv:1808.04866, 2018.
[4] Y. LeCun, L. Bottou, Y. Bengio, P. Haffner et al., “Gradient-based learning applied to document recognition,” Proceedings of the IEEE,vol. 86, no. 11, pp. 2278–2324, 1998.
[5] D. Liu, T. Miller, R. Sayeed, and K. Mandl, “Fadl: Federated-autonomous deep learning for distributed electronic health record,” arXiv preprint arXiv:1811.11400, 2018.
[6] S. Shen, S. Tople, and P. Saxena, “Auror: defending against poisoning attacks in collaborative deep learning systems,” in Proceedings of the 32nd Annual Conference on Computer Security Applications. ACM,2016, pp. 508–519.